
Veremos de qué se trata este paso inicial tan importante y necesario para comenzar un proyecto de Machine Learning. Aprendamos en qué consiste el EDA y qué técnicas utilizar. Veamos un ejemplo práctico y la manipulación de datos con Python utilizando la librería Pandas para analizar y Visualizar la información en pocos minutos.
Como siempre, podrás descargar todo el código de la Jupyter Notebook desde mi cuenta de Github (que contiene información extra). Y como BONUS encuentra una notebook con las funciones más útiles de Pandas!

¿Qué es el EDA?
Eda es la sigla en inglés para Exploratory Data Analysis y consiste en una de las primeras tareas que tiene que desempeñar el Científico de Datos. Es cuando revisamos por primera vez los datos que nos llegan, por ejemplo un archivo CSV que nos entregan y deberemos intentar comprender “¿de qué se trata?”, vislumbrar posibles patrones y reconociendo distribuciones estadísticas que puedan ser útiles en el futuro.
OJO!, lo ideal es que tengamos un objetivo que nos hayan “adjuntado” con los datos, que indique lo que se quiere conseguir a partir de esos datos. Por ejemplo, nos pasan un excel y nos dicen “Queremos predecir ventas a 30 días”, ó “Clasificar casos malignos/benignos de una enfermedad”, “Queremos identificar audiencias que van a realizar re-compra de un producto”, “queremos hacer pronóstico de fidelización de clientes/abandonos”, “Quiero detectar casos de fraude en mi sistema en tiempo real”.
EDA deconstruido
Al llegar un archivo, lo primero que deberíamos hacer es intentar responder:
- ¿Cuántos registros hay?
- ¿Son demasiado pocos?
- ¿Son muchos y no tenemos Capacidad (CPU+RAM) suficiente para procesarlo?
- ¿Están todas las filas completas ó tenemos campos con valores nulos?
- En caso que haya demasiados nulos: ¿Queda el resto de información inútil?
- ¿Que datos son discretos y cuales continuos?
- Muchas veces sirve obtener el tipo de datos: texto, int, double, float
- Si es un problema de tipo supervisado:
- ¿Cuál es la columna de “salida”? ¿binaria, multiclase?
- ¿Esta balanceado el conjunto salida?
- ¿Cuales parecen ser features importantes? ¿Cuales podemos descartar?
- ¿Siguen alguna distribución?
- ¿Hay correlación entre features (características)?
- En problemas de NLP es frecuente que existan categorías repetidas ó mal tipeadas, ó con mayusculas/minúsculas, singular y plural, por ejemplo “Abogado” y “Abogadas”, “avogado” pertenecerían todos a un mismo conjunto.
- ¿Estamos ante un problema dependiente del tiempo? Es decir un TimeSeries.
- Si fuera un problema de Visión Artificial: ¿Tenemos suficientes muestras de cada clase y variedad, para poder hacer generalizar un modelo de Machine Learning?
- ¿Cuales son los Outliers? (unos pocos datos aislados que difieren drásticamente del resto y “contaminan” ó desvían las distribuciones)
- Podemos eliminarlos? es importante conservarlos?
- son errores de carga o son reales?
- ¿Tenemos posible sesgo de datos? (por ejemplo perjudicar a clases minoritarias por no incluirlas y que el modelo de ML discrimine)
Puede ocurrir que tengamos set de datos incompletos y debamos pedir a nuestro cliente/proveedor ó interesado que nos brinde mayor información de los campos, que aporte más conocimiento ó que corrija campos.
¿Qué son los conjuntos de Train, Test y Validación en Machine Learning?
También puede que nos pasen múltiples fuentes de datos, por ejemplo un csv, un excel y el acceso a una base de datos. Entonces tendremos que hacer un paso previo de unificación de datos.
¿Qué sacamos del EDA?
El EDA será entonces una primer aproximación a los datos, ATENCIóN, si estamos mas o menos bien preparados y suponiendo una muestra de datos “suficiente”, puede que en “unas horas” tengamos ya varias conclusiones como por ejemplo:
- Esto que quiere hacer el cliente CON ESTOS DATOS es una locura imposible! (esto ocurre la mayoría de las veces jeje)
- No tenemos datos suficientes ó son de muy mala calidad, pedir más al cliente.
- Un modelo de tipo Arbol es lo más recomendado usar
- (reemplazar Arbol, por el tipo de modelo que hayamos descubierto como mejor opción!)
- No hace falta usar Machine Learning para resolver lo que pide el cliente. (ESTO ES MUY IMPORTANTE!)
- Es todo tan aleatorio que no habrá manera de detectar patrones
- Hay datos suficientes y de buena calidad como para seguir a la próxima etapa.
A estas alturas podemos saber si nos están pidiendo algo viable ó si necesitamos más datos para comenzar.
Repito por si no quedó claro: el EDA debe tomar horas, ó puede que un día, pero la idea es poder sacar algunas conclusiones rápidas para contestar al cliente si podemos seguir o no con su propuesta.
Luego del EDA, suponiendo que seguimos adelante podemos tomarnos más tiempo y analizar en mayor detalle los datos y avanzar a nuevas etapas para aplicar modelos de Machine Learning.

Técnicas para EDA
Vamos a lo práctico!, ¿Que herramientas tenemos hoy en día? La verdad es que como cada conjunto de datos suele ser único, el EDA se hace bastante “a mano”, pero podemos seguir diversos pasos ordenados para intentar acercarnos a ese objetivo que nos pasa el cliente en pocas horas.
A nivel programación y como venimos utilizando Python, encontramos a la conocida librería Pandas, que nos ayudará a manipular datos, leer y transformarlos.
Instala el ambiente de desarrollo Python en tu ordenador siguiendo esta guía
Otra de las técnicas que más nos ayudaran en el EDA es visualización de datos (que también podemos hacer con Pandas).
Finalmente podemos decir que nuestra Intuición -basada en Experiencia previa, no en corazonadas- y nuestro conocimiento de casos similares también nos pueden aportar pistas para saber si estamos ante datos de buena calidad. Por ejemplo si alguien quiere hacer reconocimiento de imágenes de tornillos y tiene 25 imágenes y con muy mala resolución podremos decir que no tenemos muestras suficientes -dado nuestro conocimiento previo de este campo-.
Vamos a la práctica!
Un EDA de pocos minutos con Pandas (Python)
Vamos a hacer un ejemplo en pandas de un EDA bastante sencillo pero con fines educativos.
Vamos a leer un csv directamente desde una URL de GitHub que contiene información geográfica básica de los países del mundo y vamos a jugar un poco con esos datos.
|
1 2 3 4 5 6 7 8 |
import pandas as pd import numpy as np import matplotlib.pyplot as plt import statsmodels.api as sm url = 'https://raw.githubusercontent.com/lorey/list-of-countries/master/csv/countries.csv' df = pd.read_csv(url, sep=";") print(df.head(5)) |

Veamos los datos básicos que nos brinda pandas:
Nombre de columnas
|
1 2 |
print('Cantidad de Filas y columnas:',df.shape) print('Nombre columnas:',df.columns) |

Columnas, nulos y tipo de datos
|
1 |
df.info() |

descripción estadística de los datos numéricos
|
1 |
df.describe() |
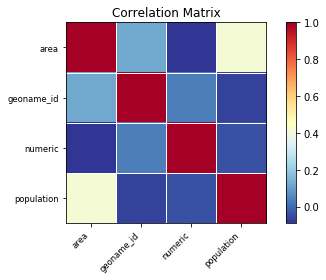
Verifiquemos si hay correlación entre los datos
|
1 2 3 |
corr = df.set_index('alpha_3').corr() sm.graphics.plot_corr(corr, xnames=list(corr.columns)) plt.show() |
Cargamos un segundo archivo csv para ahondar en el crecimiento de la población en los últimos años, filtramos a España y visualizamos
|
1 2 3 4 5 6 |
url = 'https://raw.githubusercontent.com/DrueStaples/Population_Growth/master/countries.csv' df_pop = pd.read_csv(url) print(df_pop.head(5)) df_pop_es = df_pop[df_pop["country"] == 'Spain' ] print(df_pop_es.head()) df_pop_es.drop(['country'],axis=1)['population'].plot(kind='bar') |


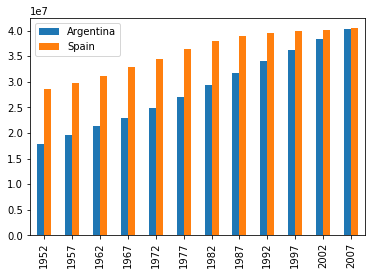
Hagamos la comparativa con otro país, por ejemplo con el crecimiento poblacional en Argentina
|
1 2 3 4 5 6 7 8 9 10 |
df_pop_ar = df_pop[(df_pop["country"] == 'Argentina')] anios = df_pop_es['year'].unique() pop_ar = df_pop_ar['population'].values pop_es = df_pop_es['population'].values df_plot = pd.DataFrame({'Argentina': pop_ar, 'Spain': pop_es}, index=anios) df_plot.plot(kind='bar') |
Ahora filtremos todos los paises hispano-hablantes
|
1 2 3 |
df_espanol = df.replace(np.nan, '', regex=True) df_espanol = df_espanol[ df_espanol['languages'].str.contains('es') ] df_espanol |

Visualizamos…
|
1 |
df_espanol.set_index('alpha_3')[['population','area']].plot(kind='bar',rot=65,figsize=(20,10)) |

Vamos a hacer detección de Outliers, (con fines educativos) en este caso definimos como limite superior (e inferior) la media más (menos) “2 veces la desviación estándar” que muchas veces es tomada como máximos de tolerancia.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
anomalies = [] # Funcion ejemplo para detección de outliers def find_anomalies(data): # Set upper and lower limit to 2 standard deviation data_std = data.std() data_mean = data.mean() anomaly_cut_off = data_std * 2 lower_limit = data_mean - anomaly_cut_off upper_limit = data_mean + anomaly_cut_off print(lower_limit.iloc[0]) print(upper_limit.iloc[0]) # Generate outliers for index, row in data.iterrows(): outlier = row # # obtener primer columna # print(outlier) if (outlier.iloc[0] > upper_limit.iloc[0]) or (outlier.iloc[0] < lower_limit.iloc[0]): anomalies.append(index) return anomalies find_anomalies(df_espanol.set_index('alpha_3')[['population']]) |
Detectamos como outliers a Brasil y a USA. Los eliminamos y graficamos ordenado por población de menor a mayor.
|
1 2 3 |
# Quitemos BRA y USA por ser outlies y volvamos a graficar: df_espanol.drop([30,233], inplace=True) df_espanol.set_index('alpha_3')[['population','area']].sort_values(["population"]).plot(kind='bar',rot=65,figsize=(20,10)) |

En pocos minutos hemos podido responder: cuántos datos tenemos, si hay nulos, los tipos de datos (entero, float, string), la correlación, hicimos visualizaciones, comparativas, manipulación de datos, detección de ouliers y volver a graficar. ¿No está nada mal, no?
Más cosas! que se suelen hacer:
Otras pruebas y gráficas que se suelen hacer son:
- Si hay datos categóricos, agruparlos, contabilizarlos y ver su relación con las clases de salida
- gráficas de distribución en el tiempo, por ejemplo si tuviéramos ventas, para tener una primera impresión sobre su estacionalidad.
- Rankings del tipo “10 productos más vendidos” ó “10 ítems con más referencias por usuario”.
- Calcular importancia de Features y descartar las menos útiles.
Conclusiones
En el artículo vimos un repaso sobre qué es y cómo lograr hacer un Análisis Exploratorio de Datos en pocos minutos. Su importancia es sobre todo la de darnos un vistazo sobre la calidad de datos que tenemos y hasta puede determinar la continuidad o no de un proyecto.
Siempre dependerá de los datos que tengamos, en cantidad y calidad y por supuesto nunca deberemos dejar de tener en vista EL OBJETIVO, el propósito que buscamos lograr. Siempre debemos apuntar a lograr eso con nuestras acciones.
Como resultado del EDA si determinamos continuar, pasaremos a una etapa en la que ya preprocesaremos los datos pensando en la entrada a un modelo (ó modelos!) de Machine Learning.
La detección de Outliers podría comentarse en un artículo completo sobre el tema… YA salió!
¿Conocías el EDA? ¿Lo utilizas en tu trabajo? Espero tus comentarios!
Suscripción al Blog
Recibe los próximos artículos sobre Machine Learning, estrategias, teoría y código Python en tu casilla de correo.
NOTA: algunos usuarios reportaron que el email de confirmación y/o posteriores a la suscripción entraron en su carpeta de SPAM. Te sugiero que revises y recomiendo que agregues nuestro remitente a tus contactos para evitar problemas. Gracias!
Recursos
Como siempre, puedes descargar la notebook relacionada con este artículo desde aquí:
BONUS track: Notebook sobre manipulación de datos con Pandas
Como Bonus…. te dejo una notebook con los Casos más comunes de uso de Manipulación de datos con Pandas!
Artículos Relacionados
Estos son otros artículos relacionados que pueden ser de tu interés:
Excelente aporte. Pues estaría muy bien un POST profundizando más sobre La detección de Outliers y el tratamiento de datos.
Perfecto!, tomo nota y escribiré uno en el futuro! Gracias Dany por el comentario
Me encantó tu análisis!!! Muy sencillo!!! Realizaré unas pruebas.
Muchas gracias!!!
Hola Angie, gracias por escribir! Luego nos cuenta cómo salió, saludos
Tengo duda sobre esta linea de codigo, para que sirve o que hace
df_espanol = df.replace(np.nan, », regex=True)
y sobre el funcionamiento de set_index()
Hola,
Primero que nada FELICITACIONES!!!!
Esta pagina esta de maravilla, me ha encantado y la recomendare a todo el mundo…
Solo que me queda una duda, que espero me puedas aclarar…
Por lo que leí, entendí que mientras mas alta sea la correlación (positiva o negativa) mayor relación tienen los datos.
Entonces:
¿Por que se recomienda eliminar las features con ALTA correlación?
¿O sea de que me servirá dejar los datos que no tienen relación entre ellos?
Saludos y gracias!
Que vainaaaa…
Que hace esta linea
df_espanol.drop([30,233], inplace=True)
de donde sale el 30 y el 233
si te fijas en el dataframe, la fila 30 corresponde a Brasil; la 233 a EE.UU. Con .drop las está eliminando, ya que las detectó como outliers.
Usando inplace=True está haciendo cambios “efectivos” en el dataframe, es decir, que a partir de esa instrucción los borra de manera definitiva. Si volvés a llamar a ese df más adelante, Brasil y EE.UU no estarán.
Me gustaría que trataras el tema de Outliers Seria muy interesante,,, yo apenas me estoy involucrando pero espero ya poder hacer algunas aplicaciones en mi trabajo
Hola Manuel, gracias por escribir. Tengo en el mapa el tema de Outliers, intentaré publicar próximamente con ejemplos.
Saludos!
Hola !antes que nada felicitaciones y mil gracias por tus posts. Un trabajazo la verdad. Aportan mucha claridad y ayuda a aprender a leer entre líneas este tipo de proyecto. En el análisis exploratorio me ha ayudado mucho estar súper pegado al usuario de negocio para validar que los datos realmente reflejan la realidad que ellos tienen en mente. Esto ayuda por un lado a asegurarte que estas considerando los datos correctos y que los entiendes (como comentas que con tener datos no es suficiente) y por otro lado consigues engagement del usuario de negocio al involucrarlo en la validación. Por último un artículo que recomiendo es el de Mashur Joshi , why son many data science project fail to deliver. Gracias !
Hola Leandro, muchas gracias por escribir y leeré ese artículo que recomiendas! Saludos
Hola Juani! bueno ya me he hecho un fanático del blog me ha servido mucho y me resulta mas fácil aprender desde aquí que de otra forma.
Antes que nada quería felicitarte y darte las gracias por el aporte a la comunidad.
Al igual que me paso anteriormente con otro data set, no se desde donde se descargan, ya que me lleva a github pero una vez allí no encuentro ningún link de descarga.
Me gustaría no molestarte con algo tan básico pero quisiera aprender bien y hacer la practica con los mismos dataset seria ideal.
Desde ya muchas gracias!
Saludos.
Buenas, en GitHub tiene la opción de ver el archivo en formato “raw” Y luego lo guardas con tu navegador!
Saludos