Ejercicio Propuesto: Clasificar imágenes de deportes
Para el ejercicio se me ocurrió crear “mi propio set MNIST” con imágenes de deportes. Para ello, seleccioné los 10 deportes más populares del mundo -según la sabiduría de internet- : Fútbol, Basket, Golf, Futbol Americano, Tenis, Fórmula 1, Ciclismo, Boxeo, Beisball y Natación (enumerados sin orden particular entre ellos).
Obtuve entre 5000 y 9000 imágenes de cada deporte, a partir de videos de Youtube (usando a FFMpeg!). Las imágenes están en tamaño <<diminuto>> de 21×28 pixeles en color y son un total de 77.000. Si bien el tamaño en pixeles puede parecer pequeño ES SUFICIENTE para que nuestra red neuronal pueda distinguirlas!!! (¿increíble, no?).
Entonces el objetivo es que nuestra máquina: “red neuronal convolucional” aprenda a clasificar -por sí sóla-, dada una nueva imagen, de qué deporte se trata.
Ejemplo de imágenes de los deportes más populares del mundo
Dividiremos el set de datos en 80-20 para entrenamiento y para test. A su vez, el conjunto de entrenamiento también lo subdividiremos en otro 80-20 para Entrenamiento y Validación en cada iteración (EPOCH) de aprendizaje.
Una muestra de las imágenes del Dataset que he titulado sportsMNIST. Contiene más de 70.000 imágenes de los 10 deportes más populares del mundo.
Requerimientos para realizar el Ejercicio
Necesitaremos por supuesto tener Python 3.6 y como lo haremos en una Notebook Jupyter, recomiendo tener instalada una suite como Anaconda, que nos facilitará las tareas.
Necesitarás descargar el archivo zip con las imágenes (están comprimidas) y decomprimirlas en el mismo directorio en donde ejecutarás la Notebook con el código. Al descomprimir, se crearán 10 subdirectorios con las imágenes: uno por cada deporte
Por más que no entiendas del todo el código sigue adelante, intentaré explicar brevemente qué hacemos paso a paso y en un próximo artículo se explicará cada parte de las CNN (Convolutional Neural Networks). También dejaré al final varios enlaces con información adicional que te ayudarán.
Esto es lo que haremos hoy:
Importar librerías
Cargar las 70.000 imágenes (en memoria!)
Crear dinámicamente las etiquetas de resultado.
Dividir en sets de Entrenamiento, Validación y Test
algo de preprocesamiento de datos
Crear el modelo de la CNN
Ejecutar nuestra máquina de aprendizaje (Entrenar la red)
Revisar los resultados obtenidos
Empecemos a programar!:
1- Importar librerías
Cargaremos las libs que utilizaremos para el ejercicio.
Recuerda tener DESCOMPRIMIDAS las imágenes!!! Y ejecutar el código en el MISMO directorio donde descomprimiste el directorio llamado “sportimages” (contiene 10 subdirectorios: uno por cada deporte).
Este proceso plt.imread(filepath) cargará a memoria en un array las 77mil imágenes, por lo que puede tomar varios minutos y consumirá algo de memoria RAM de tu ordenador.
print('suma Total de imagenes en subdirs:',sum(dircount))
leyendo imagenes de /Users/xxx/proyecto_python/sportimages/ Directorios leidos: 10 Imagenes en cada directorio [9769, 8823, 8937, 5172, 7533, 7752, 7617, 9348, 5053, 7124] suma Total de imagenes en subdirs: 77128
3- Crear etiquetas y clases
Crearemos las etiquetas en labels , es decir, le daremos valores de 0 al 9 a cada deporte. Esto lo hacemos para poder usar el algoritmo supervisado e indicar que cuando cargamos una imagen de futbol en la red, ya sabemos que corresponde con la “etiqueta 6”. Y con esa información, entrada y salida esperada, la red al entrenar, ajustará los pesos de las neuronas.
Luego convertimos las etiquetas y las imágenes en numpy array con np.array()
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
labels=[]
indice=0
forcantidad indircount:
foriinrange(cantidad):
labels.append(indice)
indice=indice+1
print("Cantidad etiquetas creadas: ",len(labels))
deportes=[]
indice=0
fordirectorio indirectories:
name=directorio.split(os.sep)
print(indice,name[len(name)-1])
deportes.append(name[len(name)-1])
indice=indice+1
y=np.array(labels)
X=np.array(images,dtype=np.uint8)#convierto de lista a numpy
# Find the unique numbers from the train labels
classes=np.unique(y)
nClasses=len(classes)
print('Total number of outputs : ',nClasses)
print('Output classes : ',classes)
Cantidad etiquetas creadas: 77128 0 golf 1 basket 2 tenis 3 natacion 4 ciclismo 5 beisball 6 futbol 7 americano 8 f1 9 boxeo Total number of outputs : 10 Output classes : [0 1 2 3 4 5 6 7 8 9]
4-Creamos sets de Entrenamiento y Test, Validación y Preprocesar
Nótese la “forma” (shape) de los arrays: veremos que son de 21×28 y por 3 pues el 3 se refiere a los 3 canales de colores que tiene cada imagen: RGB (red, green, blue) que tiene valores de 0 a 255.
Preprocesamos el valor de los pixeles y lo normalizamos para que tengan un valor entre 0 y 1, por eso dividimos en 255.
Ademas haremos el “One-Hot encoding” con to_categorical() que se refiere a convertir las etiquetas (nuestras clases) por ejemplo de fútbol un 6 a una salida de tipo (0 0 0 0 0 0 1 0 0 0) Esto es porque así funcionan mejor las redes neuronales para clasificar y se corresponde con una capa de salida de la red neuronal de 10 neuronas. NOTA: por si no lo entendiste, se pone un 1 en la “sexta posición” del array y el resto en ceros, PERO no te olvides que empieza a contar incluyendo el cero!!! por eso la “etiqueta 6” queda realmente en la séptima posición.
Training data shape : (61702, 21, 28, 3) (61702,) Testing data shape : (15426, 21, 28, 3) (15426,) Original label: 0 After conversion to one-hot: [1. 0. 0. 0. 0. 0. 0. 0. 0. 0.] (49361, 21, 28, 3) (12341, 21, 28, 3) (49361, 10) (12341, 10)
5 – Creamos la red (Aquí la Magia)
Ahora sí que nos apoyamos en Keras para crear la Convolutional Neural Network. En un futuro artículo explicaré mejor lo que se está haciendo. Por ahora “confíen” en mi:
Declaramos 3 “constantes”:
El valor inicial del learning rate INIT_LR
cantidad de epochs y
tamaño batch de imágenes a procesar batch_size (cargan en memoria).
Crearemos una primer capa de neuronas “Convolucional de 2 Dimensiones” Conv2D() , donde entrarán nuestras imágenes de 21x28x3.
Aplicaremos 32 filtros (kernel) de tamaño 3×3 (no te preocupes si aún no entiendes esto!) que detectan ciertas características de la imagen (ejemplo: lineas verticales).
Utilizaremos La función LeakyReLU como activación de las neuronas.
Haremos un MaxPooling (de 2×2) que reduce la imagen que entra de 21×28 a la mitad,(11×14) manteniendo las características “únicas” que detectó cada kernel.
Para evitar el overfitting, añadimos una técnica llamada Dropout
“Aplanamos” Flatten() los 32 filtros y creamos una capa de 32 neuronas “tradicionales” Dense()
Y finalizamos la capa de salida con 10 neuronas con activación Softmax, para que se corresponda con el “hot encoding” que hicimos antes.
Luego compilamos nuestra red sport_model.compile() y le asignamos un optimizador (en este caso de llama Adagrad).
Llegó el momento!!! con esta linea sport_model.fit() iniciaremos el entrenamiento y validación de nuestra máquina! Pensemos que introduciremos miles de imágenes, pixeles, arrays, colores… filtros y la red se irá regulando sola, “aprendiendo” los mejores pesos para las más de 150.000 interconexiones para distinguir los 10 deportes. Esto tomará tiempo en un ordenador como mi Macbook Pro (del 2016) unos 4 minutos… puede parecer mucho o muy poco… según se lo mire. NOTA: podemos ejecutar este mismo código pero utilizando GPU (en tu ordenador o en la nube) y los mismos cálculos tomaría apenas 40 segundos.
Por último guardamos la red YA ENTRENADA sport_model.save() en un formato de archivo h5py ya que nos permitirá poder utilizarla en el futuro SIN necesidad de volver a entrenar (y ahorrarnos los 4 minutos de impaciencia! ó incluso si contamos con GPU, ahorrarnos esa espera).
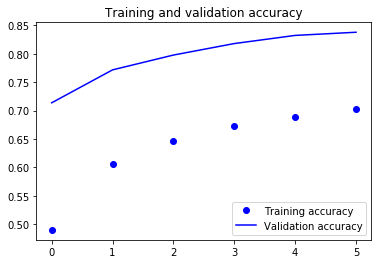
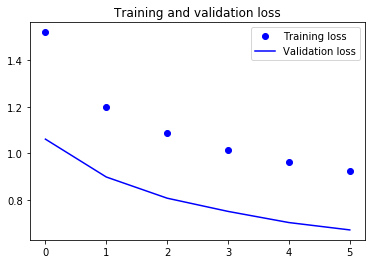
Vemos que tras 6 iteraciones completas al set de entrenamiento, logramos un valor de precisión del 70% y en el set de validación alcanza un 83%. ¿Será esto suficiente para distinguir las imágenes deportivas?
7-Resultados obtenidos
Ya con nuestra red entrenada, es la hora de la verdad: ponerla a prueba con el set de imágenes para Test que separamos al principio y que son muestras que nunca fueron “vistas” por la máquina.
15426/15426 [==============================] – 5s 310us/step Test loss: 0.6687967825782881 Test accuracy: 0.8409179307662388
En el conjunto de Testing vemos que alcanza una precisión del 84% reconociendo las imágenes de deportes. Ahora podríamos hacer un análisis más profundo, para mejorar la red, revisando los fallos que tuvimos… pero lo dejaremos para otra ocasión (BONUS: en la Jupyter Notebook verás más información con esto!) Spoiler Alert: La clase que peor detecta, son las de Fórmula 1.
Puedes probar con esta imagen de Basketball y de Fútbol a clasificarlas. En mi caso, fueron clasificadas con éxito.
En mis pruebas, a veces confundía esta imagen de Fútbol con Golf… ¿Será por el verde del campo?
Conclusiones y promesa futura!
Creamos una red neuronal “novedosa”: una red convolucional, que aplica filtros a las imágenes y es capaz de distinguir distintos deportes con un tamaño 21×28 pixels a color en tan sólo 4 minutos de entrenamiento.
Esta vez fuimos a la inversa que en otras ocasiones y antes de conocer la teoría de las redes específicas para reconocimiento de imágenes (las CNN) les he propuesto que hagamos un ejercicio práctico. Aunque pueda parecer contra-intuitivo, muchas veces este método de aprendizaje (en humanos!) funciona mejor, pues vuelve algo más dinámica la teoría. Espero que les hayan quedado algunos de los conceptos y los terminaremos de asentar en un próximo artículo (ya puedes leerlo!)
Suscripción al Blog
Recibe el próximo artículo con más teoría, prácticas y material para seguir aprendiendo Machine Learning!
92 thoughts on “Clasificación de Imágenes en Python”
Hola Juan Ignacio,
Qué interesante saber que existe este método de enseñanza top-botton. Precisamente días atrás estaba pensando que la dificultad para aprender AI para nosotros los programadores autodidactas desde tutoriales como el tuyo reside en que hay un concentrado de abstracciones muy difíciles de digerir, pues tratar de entender cada concepto abstraído resulta muy dispersivo.
Entiendo, que de modo contrario explicar cada pequeño concepto resultaría muy complicado para el instructor y se corre el riesgo de no terminar nunca de mostrar aplicaciones practicas concretas como la que enseñas en esta entrada.
Aquí es cuando quiero pedirte un consejo. Ya que mi principal interés de aprender AI reside en poder simplificar los conceptos bases de modo de poderle enseñar a niños con una metodología botton-top. ¿Cuales crees tú que son los conceptos bases que debo comenzar a investigar de modo de poder comenzar a recopilar contenido digerible más allá de un simple glosario?
Agradezco nuevamente tus esfuerzos en hacernos llegar este conocimiento.
Hola Germán, nuevamente gracias por participar del blog y escribirme!. Realmente no sé aconsejarte una mejor (ó peor) metodología de aprendizaje. Los conceptos más potentes para mi (y esto es muy subjetivo) son:
1 -Definición de Machine Learning: la máquina aprende a generalizar conceptos por sí misma y la diferencia con la programación tradicional
2 -Redes neuronales Artificiales “tradicionales” (perceptron y luego multilayer) Esto a mi particularmente me abrió la cabeza, el hecho de imitar nuestro comportamiento biológico, la función de activación y la interrelación entre neuronas
3 -Deep Learning (y surgen las redes neuronales ya más potentes y con jerarquías en sus capas)
Imagino que hay muchas otras variantes mejores, pero bueno, era por darte mi opinión.
Saludos y espero haber podido ayudar un poco. Sigamos en contacto!
Muchas gracias Juan Ignancio, no me llegó la notificación y hoy es que estoy leyendo tu respuesta.
Sería interesante poder unir un equipo de trabajo para estudiar la mejor forma de al menos “comenzar a interesar” sobre la materia al público más joven posible. A mí me preocupa mucho la brecha tecnológica que se está abriendo en Latinoamérica, porque mucha de esa información, así como muchísima de la información del mundo de la programación, están disponible de forma “marginal” en español. Y yo considero que eso colocará en gran desventaja a muchísima gente en los próximos años. Evidentemente no me preocupo únicamente por niños o personas hispanohablantes, me gustaría que cualquier persona del mundo tenga un buen acceso a esta información, porque de ello dependerá el bienestar en áreas geográficas extensas. Pero es un trabajo titánico para una sola hormiga. En cualquier caso los desafíos son siempre motivantes. Yo estoy trabajando en un código open suorce para mostrar transparencia en la gestión de proyectos y de esta manera lograr financiar cursos (entre otras cosas) que estarían a disposición de cualquiera dentro de la plataforma. Es un proyecto que lo estoy iniciando pero le tengo bastante ilusión puesta. El repositorio lo encuentras aquí https://github.com/Chococoin/CrystalChocolate.
De momento todos los recursos que estoy destinando salen de mi bolsillo y de mi tiempo. No tengo problema con eso, pero seguramente serán pocos los recursos que se puedan destinar a una sección pedagógica. Sin embargo, te invito a que discutamos mejor la forma en como podemos colaborar para ayudar a más personas a aprender todo esto.
Un cordial saludo y gracias nuevamente por tu maravilloso blog.
Ahora mismo estoy cursando IA en la UOC y estamos empezando con LISP. De momento, estoy alucinando un poco con la teoría y las prácticas, cuando tenga un rato miraré de configurar el entorno que propones y ejecutar tú código.
Hola, pues deberías crear un dataset con imágenes como las que quieras identificar y entrenar tu red (CNN). Eso o necesitaría más detalle de lo que pretendes hacer. Hay otra temática además de la clasificación de imágenes -que escribí en este artículo- que es la “detección de objetos” dentro de la imagen. Te dejo un enlace por si te sirve: Object Detection a Guide.
Hola Angel, gracias por escribir, espero que el blog sea de tu ayuda para usar CNN en Python. Mi próximo artículo comentaré mejor la teoría. Te respondo:
Al instalar el backend de tensorflow eliges si funcionará con CPU ó GPU. Si tienes, es lo mejor, pues se acelera el training de minutos a apenas segundos. Una tercer opción es usar Algún servicio en la Nube que corra con GPU. La mayoría son servicios de pago, pero ahora google ofrece un servicio limitado que sellaba Colab.
Puedes hacer Transfer learning, tanto Keras como Pytorch ofrecen hacer un “load” de esas redes pre-entrenadas para ajustarlas a tus propios intereses. Te recomiendo sobre todo que veas/uses la lib de fast.ai pues está muy enfocada en el uso “rápido” de CNN que ya vienen pre-entrenadas.
Hola Juan Ignacio.
Muy interesante, lo que pasa es que en el soprtimages.zip no hay las 70.000 imágenes, sólo hay dos directorios.
¿Es correcto?.
Gracias
Hola Jose, el archivo zip contiene 10 subdirectorios con los deportes y cada uno contiene más de 5000 imágenes. Imagino que habrás tenido algún problema con la descarga. Saludos
Hola Juan Ignacio, Tengo un problema al instalar TensorFlow en un ordenador nuevo, ¿será que TensorFlow todavía no funciona con Python 3.7?, al instalar Anaconda Python 3.7 es lo que instala por defecto, pero me da error al instalar después TensorFlow.
Gracias de antemano y felices fiestas.
Hola Jose, pues no lo sabía, pero es cierto, aún no funciona correctamente Tensorflow con Python 3.7
Por lo que leí en su web oficial/Github están trabajando en ello, pero aún da errores.
Deberías crear un entorno (environment) con python 3.6 con Tensorflow y con eso no deberías tener problemas.
Te dejo estos dos enlaces por si te ayudan:
Perfecto, gracias por la aclaración, lo hice dos veces y me salió el mismo error, por eso empecé a investigar y encontré que con 3.7, aún no funciona.
Gracias por tu ayuda.
Felices fiestas.
Felices fiestas y gracias a ti por colaborar en el blog! Saludos
Buenas Juan Ignacio, a mi me arrojaba error al importar esta libreria ->from sklearn.cross_validation import train_test_split pero se supone que es porque esta deprecated, y la nueva forma es : from sklearn.model_selection import train_test_split
Espero que le sirva a todo el mundo
Buenas tardes. Me agradaría saber si utilizando este método de clasificación puedes saber cuáles son los atributos que mejor sirven para el reconocimiento de los 10 tipos de imágenes. Gracias.
Hola JRoberto, podríamos intentar ver el resultado de las capas intermedias, luego de los kernels, para ver qué atributos destacan e intentar ver cuales se activan en cada una de las 10 categorías. Es un tema interesante y podría ser motivo de un futuro artículo en el blog (lo apunto al roadmap).
Mientras tanto, se me ocurre sugerirte una librería novedosa -aún no la he probado- que facilita la inspección de capas ocultas: Interactive convnet features visualization for Keras
Antes de nada felicitarte por tu blog, estoy empezando en este mundo y me está sirviendo de gran ayuda.
He estado practicando las redes y me surge una duda, como podemos normalizar las imágenes pero para que en lugar de que la normalización sea entre 0 y 1 fuese entre -1 y 1, por ejemplo?. He intentado hacerlo con los scaler de sklearn pero no pueden hacerlo con un array de 4D, ¿Como podría hacer esta normalización? .
Hola Fernando, gracias por escribir y por tu comentario.
Para hacer la normalización con el MinMaxScaler de sklearn debes hacer: scaler = MinMaxScaler(feature_range=(-1, 1))
al declararlo.
Como dices que tienes un arreglo en 4D puede que tengas que usar la función reshape() de numpy.
Hola Amigo buen día, espero que me ayudes con este mensaje de error, soy nuevo en esto y veo que tus, tutos son excelentes, pero me perdí por aquí… tu concejo porfa..
Traceback (most recent call last):
File “E:/Proyectos Python 2019/Face/TensorFlow/deportivo/procesar.py”, line 74, in
train_x,test_x,train_y,test_y=train_test_split(x,y,test_size=0.2)
File “C:\pyton\lib\site-packages\sklearn\model_selection_split.py”, line 2184, in train_test_split
arrays = indexable(arrays)
File “C:\pyton\lib\site-packages\sklearn\utils\validation.py”, line 260, in indexable
check_consistent_length(result)
File “C:\pyton\lib\site-packages\sklearn\utils\validation.py”, line 235, in check_consistent_length
” samples: %r” % [int(l) for l in lengths])
ValueError: Found input variables with inconsistent numbers of samples: [77128, 68192]
Hola José Flores, te respondo, por lo que pude ver, tienes diferencia en las cantidades de X e y que pasas a la función de train_test_split.
Por el código que copiaste, noté que usaste la “x” minúscula, cuando en mi código se usa en Mayúsculas y puede que eso sea la causa.
Saludos!
Hola Roberto, pues siguiendo al ejemplo del ejercicio, puedes crear un directorio, por ejemplo: “animales” y dentro con dos subdirectorios “perros” y “gatos”. Luego les cargas miles de imágenes y listo 😉
Genial tu guia pero tengo una duda en el punto 7. no me queda muy claro como hacer para mostrarle una imagen a la red y me diga que deporte es,
tu esecificas poder usar al final dos imagenes una que te la identifica como bsketball no entiendo como mostrarle las imagenes a la red para que ella me responda
Hola Andres, te cuento como hacer:
Suponiendo que ya guardaste la red entrenada, la cargas y la usas con las dos imágenes:
model = load_model('sports_mnist.h5py')
for filepath in filenames:
image = plt.imread(filepath)
image_resized = misc.imresize(image, (21, 28))
images.append(image_resized)
X = np.array(images, dtype=np.uint8) #convierto de lista a numpy
test_X = X.astype('float32')
test_X = test_X / 255.
predicted_classes = model.predict(test_X)
prediccion = predicted_classes[0] # para ver la predicción de la primera foto
prediccion
OJO que en luego del for, no me pone la tabulación de las 3 siguientes lineas (problema de WordPress… lo siento).
Luego me cuentas si te funciona bien!
Saludos
Hola mira he puesto lo que me has sugeriddo y primero me sale este error
NameError: name ‘misc’ is not defined
luego si borro el misc me sale el siguiente
could not broadcast input array from shape (21,28,4) into shape (21,28)
Hola, pues les comento que ya es un error que quedó deprecado.
Para resolverlo deben primero instalar: pip install scikit-image
En linea de comandos (terminal) en vuestro ambiente de python.
Luego en el código deben importar: from skimage.transform import resize
Y reemplazar ESA linea por esta: image_resized = resize(image, (21, 28),preserve_range=True)
Hola puedes ayudarme ,la prediccion solo me da un array y no los nombres de los labels
Hola Helen, agregué un ejemplo en la notebook de GitHub, espero que te sirva, saludos!
Tu blog es increíble, muchas gracias por el trabajo que haces.
Me ha surgido una duda e igual me puedes ayudar, he probado el código para otro repositorio de imágenes y no consigo que se haga bien la lectura, no da error, pero a la hora de crear las etiquetas me resulta imposible definir X correctamente, he valorado la posibilidad de que sea por el tamaño y las he redimensionado pero sigue igual, se te ocurre cual puede ser el motivo?
Hola Maria, gracias por escribir, Así tal cual lo cuentas no se me ocurre motivo. ¿Puedes confirmar que las imagenes son jpg? Deberías ir debutando el código e intentar comprobar si lee las imágenes.
Puedes intentar un “experimento” bien sencillo agregando sólo 1 ó dos imágenes en 1 ó 2 carpetas y comprobar si las lee.
Si tienes mas datos o te da error, me vuelves a escribir e intento ayudarte!
Saludos
Hola amigo, tu blog es bastante informativo y muy util para el aprendizaje, gracias por tu aporte, yo recien estoy comenzando en este mundo y me parece muy intereante gracias.
Hola excelente blog pero tengo una inquietud, en el momento que convertimos las etiquetas y las imágenes en numpy array con np.array() y ejecuto me sale el siguiente error:
File “”, line 20, in
X = np.array(images, dtype=np.uint8) #convierto de lista a numpy
ValueError: setting an array element with a sequence.
Hola, me gusto bastante el post, ha sido de gran ayuda.
Tengo una duda, intente hacer el código, pero con imágenes en escala de grises.
Primero me arrojo este error:
ValueError: Error when checking input: expected conv2d_1_input to have
Creo que lo solucione con:
train_X= tf.reshape(train_X,[-1,4, 45824, 1]) (eliminando una dimensión)
Pero ahora me arroja el siguiente error:
ValueError: Error when checking target: expected dense_2 to have shape (3,) but got array with shape (4,)
Pero no he podido encontrar el error, me sería de gran ayuda si usted me pudiera ayudar en la solución, o como trabajar con imágenes en escala de grises.
Mi primera pregunta es:
¿cambiaste input_shape=(21,28,3) por input_shape=(21,28,1) ?
(puesto que RGB son 3 canales mientras que grises es sólo 1)
Así vamos comprobando poco a poco
Saludos!
Si, lo cambié, ya lo solucioné. El problema era la dimensión que estaba usando lo solucione colocando la siguiente línea después de hacer el. compile():
Tengo una consulta más, ¿cuál es el código que usas para realizar los gráficos que muestra el accuracy del entrenamiento y la validación?
Me sería de gran ayuda por favor
Hola Juan, traté de correr el codigo en mi laptop pero al momento de hacer el one_hot_encoding me manda un error de memoria insuficiente,
Si trató de correr el código en La nube de Google ¿Tambien va a cargar las imagenes a la memoria RAM de ordenador?, ¿o directamente las va a cargar al servidor de Google?,es decir ¿podría correr el codigo en la nube incluso si mi memoria RAM es insuficiente?, de antemano gracias por tu respuesta.
Hola Juan. Tu programa funciona con tul conjunto de imágenes de deportes pero cuanto utilizo mi propio conjunto de imágenes (descargadas de la web) falla. ¿Qué características has de tener las imágenes? Saludos.
Hola JohnR, En principio son imágenes jpg de 21×28 pixeles en color.
Si tienes el mensaje de error, escríbeme por aqui o el formulario de contacto y en cuanto pueda lo reviso.
Saludos
El error es en esta línea:
X = np.array(images, dtype=np.uint8)
Concretamente:
Traceback (most recent call last):
File “E:\programacion\cnn-keras+tensorflow\images.py”, line 104, in
X = np.array(images, dtype=np.uint8)
ValueError: setting an array element with a sequence.
Juan, perdona no he podio estar por el tema hasta ahora. He descubierto que las imágenes que dan error son las que tienen una profundidad en bits de 8 y no de 24. ¿Se pueden modificar las de 8 para pasarlas a 24? Saludos.
Hola Juan,
¿Podrías poner el código también de la predicción de una imagen ?
Muchas gracias,
Narcis
Hola, que tal es de mucha ayuda tu código para poder comenzar a entender la clasificación multiclase. Mi problema surgió a raíz de que decide usar mi dataset con imágenes de 64x64x3 a color… al analizar el código resulta que tengo un problema en esta linea:
X = np.array(images, dtype=np.uint8) #convierto de lista a numpy
ya que la dimensión de la lista resulta solo tener (23336,64,64) en vez de esto (23336,64,64,3)… entiendo que la arquitectura necesita un tensor de 4 dimensiones si no, no funciona. ¿Alguna idea de cual pudiera ser el error o como corregir para que el arreglo tome los 3 canales de las imágenes?
Hola Juan, buen día muy buen blog me esta sirviendo mucho para mi investigación.
Tengo una duda, creo que hay un error en el código al momento de contar las imágenes, pues el print muestra esto :
Imágenes en cada directorio [9769, 8823, 8937, 5172, 7533, 7752, 7617, 9348, 5053, 7124]
cuando en la carpeta golf tiene 9758 imágenes y en el primer indice de ese array que pertenece a esa carpeta muestra 9769, una imagen de mas y en el ultimo indice muestra 7124 que hace referencia a la carpeta boxeo, que en realidad tiene 7125; una imagen menos.
Lo mismo me sucede cuando ejecuto el código con 2 carpetas de imágenes que tengo, estuve tratando de arreglarlo pero no encuentro como. Por favor a ver si me apoyas en esto.
Gracias de antemano.
Hola edgar¡ Yo tengo ese problema… de hecho me di cuenta que las categorias o clases al final no estan bien categorisadas. Como resolviste este problema?
Saludos Juan, cómo puedo hacer para pasarle la ruta de dos carpetas (clasificación binaria) con las imagenes sin tener que poner ambas carpetas en el mismo directorio del script. Gracias.
Hola, me gusta el contenido de este blog, explicas de manera detallada todos los pasos he leido las referencias y la explicacion que haces es muy clara, muchas gracias por compartir tu conocimiento, pero a la hora de poner en uso el modelo creado tengo el siguiente problema:
uso win:10, tf:2.1.0 keras:2.3.1 cuda:10.1 tarjeta de video rtx 2070 super
Internal: Invoking GPU asm compilation is supported on Cuda non-Windows platforms only
Relying on driver to perform ptx compilation. This message will be only logged once.
Amigo una consulta yo tengo un dataset de imagenes 32 X32 que son blanco y negro cual seria el tipo de modificacion paa la reutilizacion del codigo proporcionado este sitio web
Hola Ruben, gracias por escribir. Principalemente deberías cambiar el input de la red neuronal, donde pone input shape = (21,28,3)
deberías usar (32,32,1) puesto que blanco y negro sólo usa 1 canal (en ves de 3).
Saludos!
Hola Laury, gracias por comentar en el blog. Creo que tu error se debe a que no debes estar iterando en el directorio correcto. Asegurate que la variable imgpath esté apuntando al directorio que contiene las imágenes y que estés ejecutando el código Python en el directorio del proyecto y no desde otro sitio, o no será capaz de encontrar la ruta, excepto que la pongas como ruta absoluta.
Saludos!
Muchas gracias amigo, saludos desde Chile.
Tengo una consulta.. en que parte es donde cargo una imagen para saber el porcentaje de éxito. Si me puedes ayudar con eso.
Muy Buenas No8, este aporte me a ayudado un monton, ya que no lograba llevar a la practica la teoria de CNN, me queda una duda en el momento de testear una nueva imagen, como deberia llamar al modelo que esta guardado en formato h5py, se podria tbn guardar en xml o yaml ?? me sale este error, espero me puedas aclarar, gracias de antemano
NameError Traceback (most recent call last)
in
18 test_X = test_X / 255.
19
—> 20 predicted_classes = sport_model.predict(test_X)
21
22 for i, img_tagged in enumerate(predicted_classes):
Hola, super bien explicado. Llevo semanas intentando entender las CNN. Muchas gracias. Quisiera preguntarte si las CNN tienen algún requerimiento de tamaño o bandas para la clasificación?, es que tengo imágenes super grandes 640 x 640.
Hola Jorge, un ejemplo fantástico. Como siempre felicidades
Me ha encantado seguir este ejemplo….. creo que yo voy a hacer uno de clasificación de diferentes tipos de vehículos…. también presenta ciertas dificultades (por ejemplo camión/autobús, moto/bicicleta….) al igual que en este ejemplo es difícil diferenciar entre golf y futbol. Muy interesante…..
Lo he evolucionado un poco, te sugiero que pruebes esta configuración de red y que entrenes con el clasificador adam,…. he conseguido un accuracy del 99% sin sobreajuste (al pasar los datos de test me mantiene ese accuracy por lo que creo que no sobreajusta,…. sino con los datos de test debería dar un accuracy pésimo).
Eso si,…. el tiempo de entrenamiento ronda 1 hora sin GPU…. da para tomarse un café primero y ducharse después…. jejeje pero el resultado merece la pena, menos de 130 imágenes de las 15000 de test son mal clasificadas….
print (“Ya se ha compilado el modelo, ahora procedemos a su entrenamiento.\n”);
sport_train = sport_model.fit(train_X, train_label, batch_size=batch_size,epochs=epochs,verbose=1,validation_data=(valid_X, valid_label))
test_loss, test_acc = sport_model.evaluate(valid_X, valid_label)
print(‘\Accuracy del set de validación:’, test_acc)
Hola!, recién empiezo en este mundillo, me considero un usuario de python que recien acaba de entrar en el rango de amateur en lo que a programación en python se refiere, me gustaria saber que clase de conocimientos debería de tener para poder llevar a cabo algo así por mi propia cuenta, tanto en el ámbito matemático como en programación, un saludo y gracias de antemano!
Hola. Soy nueva en esto y creo que encontré un error en el código, primero creí porque yo hice unos cambios para poder cargar las imágenes en diferente tamaño, pero sale lo mismo si lo hago sin modificar nada, pero subiendo carpetas con pocas imágenes y es que la ultima imagen de la siguiente carpeta se etiqueta como si fuese de la carpeta actual, por ejemplo si esta leyendo la carpeta fútbol y luego sigue la de básquet, la primera imagen de básquet queda dentro de la del directorio anterior
Found 24 images belonging to 2 classes.
leyendo imagenes de ./PROBAR/entrenamiento2enf\
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (1).JPG
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot 1
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (10).JPG
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (11).JPG
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (12).JPG
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (2).JPG
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (3).JPG
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (4).JPG
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (5).JPG
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (6).JPG
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (7).JPG
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (8).JPG
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (9).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (12).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy 12
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (13).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (14).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (15).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (16).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (17).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (18).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (19).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (20).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (21).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (22).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (23).JPG
Directorios leidos: 2
Imagenes en cada directorio [13, 11]
suma Total de imagenes en subdirs: 24
eso salió con los cambios que yo hice y sin hacer cambios sale esto, pero en si es el mismo error. Espero puedas ayudarme pronto.
leyendo imagenes de C:\Users\Gabri\Documents\TODO\PROBAR\
C:\Users\Gabri\Documents\TODO\TRABAJO DE GRADO I\PROBAR\TomatoBacterialspot 1
C:\Users\Gabri\Documents\TODO\TRABAJO DE GRADO I\PROBAR\Tomatohealthy 12
Directorios leidos: 2
Imagenes en cada directorio [13, 11]
suma Total de imagenes en subdirs: 24
Como sabe el programa que una imagen que le has pasado para entrenar es tenis o baloncesto, porque hasta donde he entendido tu le pasas las imagenes y le dices que hay 10 tipos de deportes pero no le dices si el 1 es tenis el 3 baloncesto etc, ni posteriormente sabe cada imagen a que numero ir.
Hola amigo, excelente tutorial, pero tengo una pregunta.
Como ejecuto la red neuronal ya entrenada desde otro archivo, pasándole un nuevo archivo de prueba para que valide?
Hola Victor, si vas a la Jupyter Notebook en GitHub del artículo, verás que muestra cómo guardar la red neuronal (en un archivo h5py) y luego la usa para hacer predicción de “nuevas imágenes”.
Saludos,
me sale este error, a que se debe ayudeme porfavor.
28
29 dircount = dircount[1:]
—> 30 dircount[0]=dircount[0]+1
31 print(‘Directorios leidos:’,len(directories))
32 print(“Imagenes en cada directorio”, dircount)
Hola, estoy intentado realizar este ejercicio con solo dos directorios en vez de 10.
Me aparece el siguiente error:
ValueError: setting an array element with a sequence. The requested array has an inhomogeneous shape after 1 dimensions. The detected shape was (47,) + inhomogeneous part.
debido a la línea:
X = np.array(images, dtype=np.uint8) #convierto de lista a numpy
Buenas, saludos.
muy interesante el articulo publicado, para una persona que se inicia en estos temas es bastante acogedor, sin embargo me atreveria a preguntarle, para la tecnica de validacion por matriz de confusion, que es lo que deberia tomar en cuenta?.
gracias y saludos de antemano.
Hola Juan Ignacio
Mi primera vez con este lio, y me parce «acojo…nante» tu trabajo, GRACIAS
Pero necesito que me digas como puedo probar una imagen cualquiera contra el modelo… soy encapad.
Soy un COMPLETO ignorante en esto y me he decidido a «copiar» este ejemplo y tratar de entenderlo con posterioridad…
GRACIAS








Hola Juan Ignacio,
Qué interesante saber que existe este método de enseñanza top-botton. Precisamente días atrás estaba pensando que la dificultad para aprender AI para nosotros los programadores autodidactas desde tutoriales como el tuyo reside en que hay un concentrado de abstracciones muy difíciles de digerir, pues tratar de entender cada concepto abstraído resulta muy dispersivo.
Entiendo, que de modo contrario explicar cada pequeño concepto resultaría muy complicado para el instructor y se corre el riesgo de no terminar nunca de mostrar aplicaciones practicas concretas como la que enseñas en esta entrada.
Aquí es cuando quiero pedirte un consejo. Ya que mi principal interés de aprender AI reside en poder simplificar los conceptos bases de modo de poderle enseñar a niños con una metodología botton-top. ¿Cuales crees tú que son los conceptos bases que debo comenzar a investigar de modo de poder comenzar a recopilar contenido digerible más allá de un simple glosario?
Agradezco nuevamente tus esfuerzos en hacernos llegar este conocimiento.
Hola Germán, nuevamente gracias por participar del blog y escribirme!. Realmente no sé aconsejarte una mejor (ó peor) metodología de aprendizaje. Los conceptos más potentes para mi (y esto es muy subjetivo) son:
Imagino que hay muchas otras variantes mejores, pero bueno, era por darte mi opinión.
Saludos y espero haber podido ayudar un poco. Sigamos en contacto!
Muchas gracias Juan Ignancio, no me llegó la notificación y hoy es que estoy leyendo tu respuesta.
Sería interesante poder unir un equipo de trabajo para estudiar la mejor forma de al menos “comenzar a interesar” sobre la materia al público más joven posible. A mí me preocupa mucho la brecha tecnológica que se está abriendo en Latinoamérica, porque mucha de esa información, así como muchísima de la información del mundo de la programación, están disponible de forma “marginal” en español. Y yo considero que eso colocará en gran desventaja a muchísima gente en los próximos años. Evidentemente no me preocupo únicamente por niños o personas hispanohablantes, me gustaría que cualquier persona del mundo tenga un buen acceso a esta información, porque de ello dependerá el bienestar en áreas geográficas extensas. Pero es un trabajo titánico para una sola hormiga. En cualquier caso los desafíos son siempre motivantes. Yo estoy trabajando en un código open suorce para mostrar transparencia en la gestión de proyectos y de esta manera lograr financiar cursos (entre otras cosas) que estarían a disposición de cualquiera dentro de la plataforma. Es un proyecto que lo estoy iniciando pero le tengo bastante ilusión puesta. El repositorio lo encuentras aquí https://github.com/Chococoin/CrystalChocolate.
De momento todos los recursos que estoy destinando salen de mi bolsillo y de mi tiempo. No tengo problema con eso, pero seguramente serán pocos los recursos que se puedan destinar a una sección pedagógica. Sin embargo, te invito a que discutamos mejor la forma en como podemos colaborar para ayudar a más personas a aprender todo esto.
Un cordial saludo y gracias nuevamente por tu maravilloso blog.
Hola Juan,
Muy interesante el artículo.
Ahora mismo estoy cursando IA en la UOC y estamos empezando con LISP. De momento, estoy alucinando un poco con la teoría y las prácticas, cuando tenga un rato miraré de configurar el entorno que propones y ejecutar tú código.
¡Un abrazo!
Hola David!, gracias por estar siempre presente y compartiendo tus experiencias!
A decir verdad me tendrás que enseñar LISP tu a mi! Abrazo!
gracias por el tiempo , y los conocimientos.. , podrías subir algo de identificación de figuras geométricas utilizando imagenes en tensorflow.
Hola, pues deberías crear un dataset con imágenes como las que quieras identificar y entrenar tu red (CNN). Eso o necesitaría más detalle de lo que pretendes hacer. Hay otra temática además de la clasificación de imágenes -que escribí en este artículo- que es la “detección de objetos” dentro de la imagen. Te dejo un enlace por si te sirve: Object Detection a Guide.
Hola Excelente articulo, he visto las CNN con MatLab pero no en Python, un par de preguntas:
Has pensado en usar por defecto la GPU dedicada cuando exista para que sea mas rapido el entrenamiento????
Sabes como hacer Transfer Learning de otra red ya entrenada tipo AlexNet con Python??
Saludos desde mexico
Hola Angel, gracias por escribir, espero que el blog sea de tu ayuda para usar CNN en Python. Mi próximo artículo comentaré mejor la teoría. Te respondo:
Al instalar el backend de tensorflow eliges si funcionará con CPU ó GPU. Si tienes, es lo mejor, pues se acelera el training de minutos a apenas segundos. Una tercer opción es usar Algún servicio en la Nube que corra con GPU. La mayoría son servicios de pago, pero ahora google ofrece un servicio limitado que sellaba Colab.
Puedes hacer Transfer learning, tanto Keras como Pytorch ofrecen hacer un “load” de esas redes pre-entrenadas para ajustarlas a tus propios intereses. Te recomiendo sobre todo que veas/uses la lib de fast.ai pues está muy enfocada en el uso “rápido” de CNN que ya vienen pre-entrenadas.
Hola Juan Ignacio.
Muy interesante, lo que pasa es que en el soprtimages.zip no hay las 70.000 imágenes, sólo hay dos directorios.
¿Es correcto?.
Gracias
Hola Jose, el archivo zip contiene 10 subdirectorios con los deportes y cada uno contiene más de 5000 imágenes. Imagino que habrás tenido algún problema con la descarga. Saludos
Efectivamente Juan Ignacio, el problema era mio.
Muchas gracias, estupendo trabajo.
Gracias.
Hola, que hiciste para resolver el problema? me pasa lo mismo. Gracias!
Hola Juan Ignacio, Tengo un problema al instalar TensorFlow en un ordenador nuevo, ¿será que TensorFlow todavía no funciona con Python 3.7?, al instalar Anaconda Python 3.7 es lo que instala por defecto, pero me da error al instalar después TensorFlow.
Gracias de antemano y felices fiestas.
Hola Jose, pues no lo sabía, pero es cierto, aún no funciona correctamente Tensorflow con Python 3.7
Por lo que leí en su web oficial/Github están trabajando en ello, pero aún da errores.
Deberías crear un entorno (environment) con python 3.6 con Tensorflow y con eso no deberías tener problemas.
Te dejo estos dos enlaces por si te ayudan:
Saludos
Perfecto, gracias por la aclaración, lo hice dos veces y me salió el mismo error, por eso empecé a investigar y encontré que con 3.7, aún no funciona.
Gracias por tu ayuda.
Felices fiestas.
Felices fiestas y gracias a ti por colaborar en el blog! Saludos
Buenas Juan Ignacio, a mi me arrojaba error al importar esta libreria ->from sklearn.cross_validation import train_test_split pero se supone que es porque esta deprecated, y la nueva forma es : from sklearn.model_selection import train_test_split
Espero que le sirva a todo el mundo
Genial Raúl! un gran aporte!! muchas gracias
Buenas tardes. Me agradaría saber si utilizando este método de clasificación puedes saber cuáles son los atributos que mejor sirven para el reconocimiento de los 10 tipos de imágenes. Gracias.
Hola JRoberto, podríamos intentar ver el resultado de las capas intermedias, luego de los kernels, para ver qué atributos destacan e intentar ver cuales se activan en cada una de las 10 categorías. Es un tema interesante y podría ser motivo de un futuro artículo en el blog (lo apunto al roadmap).
Mientras tanto, se me ocurre sugerirte una librería novedosa -aún no la he probado- que facilita la inspección de capas ocultas: Interactive convnet features visualization for Keras
Hola Juan Ignacio,
Antes de nada felicitarte por tu blog, estoy empezando en este mundo y me está sirviendo de gran ayuda.
He estado practicando las redes y me surge una duda, como podemos normalizar las imágenes pero para que en lugar de que la normalización sea entre 0 y 1 fuese entre -1 y 1, por ejemplo?. He intentado hacerlo con los scaler de sklearn pero no pueden hacerlo con un array de 4D, ¿Como podría hacer esta normalización? .
Muchas gracias y enhorabuena por el blog.
Hola Fernando, gracias por escribir y por tu comentario.
Para hacer la normalización con el MinMaxScaler de sklearn debes hacer:
scaler = MinMaxScaler(feature_range=(-1, 1))al declararlo.
Como dices que tienes un arreglo en 4D puede que tengas que usar la función reshape() de numpy.
Te dejo otro enlace que también puede ser útil: Normalize Time Series
Saludos y espero sigamos conectados por el blog!
Hola Amigo buen día, espero que me ayudes con este mensaje de error, soy nuevo en esto y veo que tus, tutos son excelentes, pero me perdí por aquí… tu concejo porfa..
train_x,test_x,train_y,test_y=train_test_split(x,y,test_size=0.2)
Traceback (most recent call last):
File “E:/Proyectos Python 2019/Face/TensorFlow/deportivo/procesar.py”, line 74, in
train_x,test_x,train_y,test_y=train_test_split(x,y,test_size=0.2)
File “C:\pyton\lib\site-packages\sklearn\model_selection_split.py”, line 2184, in train_test_split
arrays = indexable(arrays)
File “C:\pyton\lib\site-packages\sklearn\utils\validation.py”, line 260, in indexable
check_consistent_length(result)
File “C:\pyton\lib\site-packages\sklearn\utils\validation.py”, line 235, in check_consistent_length
” samples: %r” % [int(l) for l in lengths])
ValueError: Found input variables with inconsistent numbers of samples: [77128, 68192]
Hola José Flores, te respondo, por lo que pude ver, tienes diferencia en las cantidades de X e y que pasas a la función de train_test_split.
Por el código que copiaste, noté que usaste la “x” minúscula, cuando en mi código se usa en Mayúsculas y puede que eso sea la causa.
Saludos!
Hola una pregunta, al igual que la mayoria estoy aprendiendo, ya entrene la red, pero me queda la duda como la pruebo con mis propias fotos ??
Hola Roberto, pues siguiendo al ejemplo del ejercicio, puedes crear un directorio, por ejemplo: “animales” y dentro con dos subdirectorios “perros” y “gatos”. Luego les cargas miles de imágenes y listo 😉
Genial tu guia pero tengo una duda en el punto 7. no me queda muy claro como hacer para mostrarle una imagen a la red y me diga que deporte es,
tu esecificas poder usar al final dos imagenes una que te la identifica como bsketball no entiendo como mostrarle las imagenes a la red para que ella me responda
Hola Andres, te cuento como hacer:
Suponiendo que ya guardaste la red entrenada, la cargas y la usas con las dos imágenes:
model = load_model('sports_mnist.h5py')
images=[]
filenames = ['test_futbol.png','test_basket.png']
for filepath in filenames:
image = plt.imread(filepath)
image_resized = misc.imresize(image, (21, 28))
images.append(image_resized)
X = np.array(images, dtype=np.uint8) #convierto de lista a numpy
test_X = X.astype('float32')
test_X = test_X / 255.
predicted_classes = model.predict(test_X)
prediccion = predicted_classes[0] # para ver la predicción de la primera foto
prediccion
OJO que en luego del for, no me pone la tabulación de las 3 siguientes lineas (problema de WordPress… lo siento).
Luego me cuentas si te funciona bien!
Saludos
Hola mira he puesto lo que me has sugeriddo y primero me sale este error
NameError: name ‘misc’ is not defined
luego si borro el misc me sale el siguiente
could not broadcast input array from shape (21,28,4) into shape (21,28)
Agradeceria tu ayuda
A mi me sale el mismo error… Esperemos la respuesta de nuestro amigo Na8
Hola, pues les comento que ya es un error que quedó deprecado.
Para resolverlo deben primero instalar:
pip install scikit-imageEn linea de comandos (terminal) en vuestro ambiente de python.
Luego en el código deben importar:
from skimage.transform import resizeY reemplazar ESA linea por esta:
image_resized = resize(image, (21, 28),preserve_range=True)Hola puedes ayudarme ,la prediccion solo me da un array y no los nombres de los labels
Hola Helen, agregué un ejemplo en la notebook de GitHub, espero que te sirva, saludos!
Tu blog es increíble, muchas gracias por el trabajo que haces.
Me ha surgido una duda e igual me puedes ayudar, he probado el código para otro repositorio de imágenes y no consigo que se haga bien la lectura, no da error, pero a la hora de crear las etiquetas me resulta imposible definir X correctamente, he valorado la posibilidad de que sea por el tamaño y las he redimensionado pero sigue igual, se te ocurre cual puede ser el motivo?
Muchas gracias
Hola Maria, gracias por escribir, Así tal cual lo cuentas no se me ocurre motivo. ¿Puedes confirmar que las imagenes son jpg? Deberías ir debutando el código e intentar comprobar si lee las imágenes.
Puedes intentar un “experimento” bien sencillo agregando sólo 1 ó dos imágenes en 1 ó 2 carpetas y comprobar si las lee.
Si tienes mas datos o te da error, me vuelves a escribir e intento ayudarte!
Saludos
Hola amigo, tu blog es bastante informativo y muy util para el aprendizaje, gracias por tu aporte, yo recien estoy comenzando en este mundo y me parece muy intereante gracias.
Hola Josep, gracias por escribir, espero poder ayudarte a introducirte en este nuevo mundo 🙂
Saludos
Hola excelente blog pero tengo una inquietud, en el momento que convertimos las etiquetas y las imágenes en numpy array con np.array() y ejecuto me sale el siguiente error:
File “”, line 20, in
X = np.array(images, dtype=np.uint8) #convierto de lista a numpy
ValueError: setting an array element with a sequence.
Muchas gracias.
Me sale el mismo error. ¿Alguien tiene la solución?
Por favor, intenta verificar si el código está corregido en el archivo de Github https://github.com/jbagnato/machine-learning/blob/master/Ejercicio_CNN.ipynb
Por favor, intenta verificar si el código está corregido en el archivo de Github https://github.com/jbagnato/machine-learning/blob/master/Ejercicio_CNN.ipynb
Tengo este mismo error y no he conseguido solucionarlo, en Github https://github.com/jbagnato/machine-learning/blob/master/Ejercicio_CNN.ipynb no esta corregido el error.
Hola, justo estoy con días de mucho trabajo, pero intentaré mirarlo el fin de semana
Hola, me gusto bastante el post, ha sido de gran ayuda.
Tengo una duda, intente hacer el código, pero con imágenes en escala de grises.
Primero me arrojo este error:
ValueError: Error when checking input: expected conv2d_1_input to have
Creo que lo solucione con:
train_X= tf.reshape(train_X,[-1,4, 45824, 1]) (eliminando una dimensión)
Pero ahora me arroja el siguiente error:
ValueError: Error when checking target: expected dense_2 to have shape (3,) but got array with shape (4,)
Pero no he podido encontrar el error, me sería de gran ayuda si usted me pudiera ayudar en la solución, o como trabajar con imágenes en escala de grises.
Mi primera pregunta es:
¿cambiaste input_shape=(21,28,3) por input_shape=(21,28,1) ?
(puesto que RGB son 3 canales mientras que grises es sólo 1)
Así vamos comprobando poco a poco
Saludos!
Si, lo cambié, ya lo solucioné. El problema era la dimensión que estaba usando lo solucione colocando la siguiente línea después de hacer el. compile():
train_X = train_X.reshape(train_X.shape[0], 4, int(Fil),1).astype(‘float32’)
Tengo una consulta más, ¿cuál es el código que usas para realizar los gráficos que muestra el accuracy del entrenamiento y la validación?
Me sería de gran ayuda por favor
Hola Juan, traté de correr el codigo en mi laptop pero al momento de hacer el one_hot_encoding me manda un error de memoria insuficiente,
Si trató de correr el código en La nube de Google ¿Tambien va a cargar las imagenes a la memoria RAM de ordenador?, ¿o directamente las va a cargar al servidor de Google?,es decir ¿podría correr el codigo en la nube incluso si mi memoria RAM es insuficiente?, de antemano gracias por tu respuesta.
Si lo ejecutas en la nube de Google, con colab, utilizará la memoria, disco y cpu/GPU de la nube! tu máquina no se verá afectada para nada!!
Saludos
NameError Traceback (most recent call last)
in
—-> 1 model = load_model(‘sports_mnist.h5py’)
2
3 images=[]
4 filenames = [‘test_basket.png’]
5
NameError: name ‘load_model’ is not defined—————
como puedo solucionarlo?? Gracias por su tiempo
Hola Juan. Tu programa funciona con tul conjunto de imágenes de deportes pero cuanto utilizo mi propio conjunto de imágenes (descargadas de la web) falla. ¿Qué características has de tener las imágenes? Saludos.
Hola JohnR, En principio son imágenes jpg de 21×28 pixeles en color.
Si tienes el mensaje de error, escríbeme por aqui o el formulario de contacto y en cuanto pueda lo reviso.
Saludos
El error es en esta línea:
X = np.array(images, dtype=np.uint8)
Concretamente:
Traceback (most recent call last):
File “E:\programacion\cnn-keras+tensorflow\images.py”, line 104, in
X = np.array(images, dtype=np.uint8)
ValueError: setting an array element with a sequence.
Por favor, intenta verificar si el código está corregido en el archivo de Github https://github.com/jbagnato/machine-learning/blob/master/Ejercicio_CNN.ipynb
Juan, perdona no he podio estar por el tema hasta ahora. He descubierto que las imágenes que dan error son las que tienen una profundidad en bits de 8 y no de 24. ¿Se pueden modificar las de 8 para pasarlas a 24? Saludos.
Hola Juan,
¿Podrías poner el código también de la predicción de una imagen ?
Muchas gracias,
Narcis
Hola, que tal es de mucha ayuda tu código para poder comenzar a entender la clasificación multiclase. Mi problema surgió a raíz de que decide usar mi dataset con imágenes de 64x64x3 a color… al analizar el código resulta que tengo un problema en esta linea:
X = np.array(images, dtype=np.uint8) #convierto de lista a numpy
ya que la dimensión de la lista resulta solo tener (23336,64,64) en vez de esto (23336,64,64,3)… entiendo que la arquitectura necesita un tensor de 4 dimensiones si no, no funciona. ¿Alguna idea de cual pudiera ser el error o como corregir para que el arreglo tome los 3 canales de las imágenes?
Saludos.
Tengo el mismo problema! Si alguien encontro la solucion, seria de mucha ayuda 🙂
Hola Juan, buen día muy buen blog me esta sirviendo mucho para mi investigación.
Tengo una duda, creo que hay un error en el código al momento de contar las imágenes, pues el print muestra esto :
Imágenes en cada directorio [9769, 8823, 8937, 5172, 7533, 7752, 7617, 9348, 5053, 7124]
cuando en la carpeta golf tiene 9758 imágenes y en el primer indice de ese array que pertenece a esa carpeta muestra 9769, una imagen de mas y en el ultimo indice muestra 7124 que hace referencia a la carpeta boxeo, que en realidad tiene 7125; una imagen menos.
Lo mismo me sucede cuando ejecuto el código con 2 carpetas de imágenes que tengo, estuve tratando de arreglarlo pero no encuentro como. Por favor a ver si me apoyas en esto.
Gracias de antemano.
Juan, tengo un problema, al momento del procesamiento de las imagenes, me sale un error en esto :
in
114
115
–> 116 train_X = train_X.astype(‘float32’)
117 test_X = test_X.astype(‘float32’)
118 train_X = train_X / 255.
tengo imagenes de 256 x 256 con profundidad de bits de 24, por favor tu apoyo
Hola edgar¡ Yo tengo ese problema… de hecho me di cuenta que las categorias o clases al final no estan bien categorisadas. Como resolviste este problema?
Hola, juan me di cuenta de esto tambien… ¿como lo solucionaste?
Saludos Juan, cómo puedo hacer para pasarle la ruta de dos carpetas (clasificación binaria) con las imagenes sin tener que poner ambas carpetas en el mismo directorio del script. Gracias.
Hola, me gusta el contenido de este blog, explicas de manera detallada todos los pasos he leido las referencias y la explicacion que haces es muy clara, muchas gracias por compartir tu conocimiento, pero a la hora de poner en uso el modelo creado tengo el siguiente problema:
uso win:10, tf:2.1.0 keras:2.3.1 cuda:10.1 tarjeta de video rtx 2070 super
Internal: Invoking GPU asm compilation is supported on Cuda non-Windows platforms only
Relying on driver to perform ptx compilation. This message will be only logged once.
Amigo una consulta yo tengo un dataset de imagenes 32 X32 que son blanco y negro cual seria el tipo de modificacion paa la reutilizacion del codigo proporcionado este sitio web
Hola Ruben, gracias por escribir. Principalemente deberías cambiar el input de la red neuronal, donde pone input shape = (21,28,3)
deberías usar (32,32,1) puesto que blanco y negro sólo usa 1 canal (en ves de 3).
Saludos!
Hola, ayudaa
in
28
29 dircount = dircount[1:]
—> 30 dircount[0]= dircount[0]+1
31 print(‘Directorios leidos:’,len(directories))
32 print(«Imagenes en cada directorio», dircount)
IndexError: list index out of range
Hola Laury, gracias por comentar en el blog. Creo que tu error se debe a que no debes estar iterando en el directorio correcto. Asegurate que la variable imgpath esté apuntando al directorio que contiene las imágenes y que estés ejecutando el código Python en el directorio del proyecto y no desde otro sitio, o no será capaz de encontrar la ruta, excepto que la pongas como ruta absoluta.
Saludos!
Muchas gracias amigo, saludos desde Chile.
Tengo una consulta.. en que parte es donde cargo una imagen para saber el porcentaje de éxito. Si me puedes ayudar con eso.
Hola Ignacio, agregué al notebook Ejercicio_CNN de Github un ejemplo para hacer la clasificación en imágenes nuevas.
Saludos!
Muy Buenas No8, este aporte me a ayudado un monton, ya que no lograba llevar a la practica la teoria de CNN, me queda una duda en el momento de testear una nueva imagen, como deberia llamar al modelo que esta guardado en formato h5py, se podria tbn guardar en xml o yaml ?? me sale este error, espero me puedas aclarar, gracias de antemano
NameError Traceback (most recent call last)
in
18 test_X = test_X / 255.
19
—> 20 predicted_classes = sport_model.predict(test_X)
21
22 for i, img_tagged in enumerate(predicted_classes):
NameError: name ‘sport_model’ is not defined
Hola, super bien explicado. Llevo semanas intentando entender las CNN. Muchas gracias. Quisiera preguntarte si las CNN tienen algún requerimiento de tamaño o bandas para la clasificación?, es que tengo imágenes super grandes 640 x 640.
Lograste tener una solución en la distribución y lectura de cada clase?
Hola Jorge, un ejemplo fantástico. Como siempre felicidades
Me ha encantado seguir este ejemplo….. creo que yo voy a hacer uno de clasificación de diferentes tipos de vehículos…. también presenta ciertas dificultades (por ejemplo camión/autobús, moto/bicicleta….) al igual que en este ejemplo es difícil diferenciar entre golf y futbol. Muy interesante…..
Lo he evolucionado un poco, te sugiero que pruebes esta configuración de red y que entrenes con el clasificador adam,…. he conseguido un accuracy del 99% sin sobreajuste (al pasar los datos de test me mantiene ese accuracy por lo que creo que no sobreajusta,…. sino con los datos de test debería dar un accuracy pésimo).
Eso si,…. el tiempo de entrenamiento ronda 1 hora sin GPU…. da para tomarse un café primero y ducharse después…. jejeje pero el resultado merece la pena, menos de 130 imágenes de las 15000 de test son mal clasificadas….
#============================================================
#
Modelo de Red
#
#============================================================
sport_model = Sequential()
sport_model.add(Conv2D(64, kernel_size=(3, 3),activation=’relu’, strides=1, padding=’same’,input_shape=(21,28,3)))
sport_model.add(BatchNormalization())
sport_model.add(Conv2D(filters=64, kernel_size=(3, 3), activation=’relu’, strides=1, padding=’same’))
sport_model.add(BatchNormalization())
sport_model.add(Dropout(0.25))
sport_model.add(Conv2D(filters=64, kernel_size=(3, 3), activation=’relu’, strides=1, padding=’same’))
sport_model.add(MaxPooling2D(pool_size=(2, 2)))
sport_model.add(Dropout(0.25))
sport_model.add(Conv2D(filters=128, kernel_size=(3, 3), activation=’relu’, strides=1, padding=’same’))
sport_model.add(BatchNormalization())
sport_model.add(Dropout(0.25))
sport_model.add(Flatten())
sport_model.add(Dense(32, activation=’linear’))
sport_model.add(LeakyReLU(alpha=0.2))
sport_model.add(BatchNormalization())
sport_model.add(Dropout(0.5))
sport_model.add(Dense(32, activation=’linear’))
sport_model.add(LeakyReLU(alpha=0.2))
sport_model.add(BatchNormalization())
sport_model.add(Dropout(0.5))
sport_model.add(Dense(nClasses, activation=’softmax’))
sport_model.summary()
#====================================================================
#
Compilacion y entrenamiento de la red
#
#====================================================================
sport_model.compile(loss=keras.losses.categorical_crossentropy, optimizer=’adam’, metrics=[‘accuracy’])
print (“Ya se ha compilado el modelo, ahora procedemos a su entrenamiento.\n”);
sport_train = sport_model.fit(train_X, train_label, batch_size=batch_size,epochs=epochs,verbose=1,validation_data=(valid_X, valid_label))
test_loss, test_acc = sport_model.evaluate(valid_X, valid_label)
print(‘\Accuracy del set de validación:’, test_acc)
Buenas, muy buen articulo, pero no acabo de entender en que se diferencian las imágenes de entrenamiento con las de test y con las de validación, leído este artículo: https://www.aprendemachinelearning.com/sets-de-entrenamiento-test-validacion-cruzada/
pero no acabo de entender muy bien en que se diferencian.
Hola!, recién empiezo en este mundillo, me considero un usuario de python que recien acaba de entrar en el rango de amateur en lo que a programación en python se refiere, me gustaria saber que clase de conocimientos debería de tener para poder llevar a cabo algo así por mi propia cuenta, tanto en el ámbito matemático como en programación, un saludo y gracias de antemano!
Hola. Soy nueva en esto y creo que encontré un error en el código, primero creí porque yo hice unos cambios para poder cargar las imágenes en diferente tamaño, pero sale lo mismo si lo hago sin modificar nada, pero subiendo carpetas con pocas imágenes y es que la ultima imagen de la siguiente carpeta se etiqueta como si fuese de la carpeta actual, por ejemplo si esta leyendo la carpeta fútbol y luego sigue la de básquet, la primera imagen de básquet queda dentro de la del directorio anterior
Found 24 images belonging to 2 classes.
leyendo imagenes de ./PROBAR/entrenamiento2enf\
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (1).JPG
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot 1
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (10).JPG
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (11).JPG
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (12).JPG
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (2).JPG
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (3).JPG
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (4).JPG
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (5).JPG
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (6).JPG
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (7).JPG
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (8).JPG
./PROBAR/entrenamiento2enf\Tomato___Bacterial_spot\tomato_bacterial_spot (9).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (12).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy 12
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (13).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (14).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (15).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (16).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (17).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (18).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (19).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (20).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (21).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (22).JPG
./PROBAR/entrenamiento2enf\Tomato___healthy\Tomato_healthly (23).JPG
Directorios leidos: 2
Imagenes en cada directorio [13, 11]
suma Total de imagenes en subdirs: 24
eso salió con los cambios que yo hice y sin hacer cambios sale esto, pero en si es el mismo error. Espero puedas ayudarme pronto.
leyendo imagenes de C:\Users\Gabri\Documents\TODO\PROBAR\
C:\Users\Gabri\Documents\TODO\TRABAJO DE GRADO I\PROBAR\TomatoBacterialspot 1
C:\Users\Gabri\Documents\TODO\TRABAJO DE GRADO I\PROBAR\Tomatohealthy 12
Directorios leidos: 2
Imagenes en cada directorio [13, 11]
suma Total de imagenes en subdirs: 24
Saludos.
Mañana lo reviso y te digo, saludos
Me ocurre lo mismo, ¿pudiste solucionarlo?
Muy bien articulo pero tengo unas dudas.
Como sabe el programa que una imagen que le has pasado para entrenar es tenis o baloncesto, porque hasta donde he entendido tu le pasas las imagenes y le dices que hay 10 tipos de deportes pero no le dices si el 1 es tenis el 3 baloncesto etc, ni posteriormente sabe cada imagen a que numero ir.
Saludos.
Hola, gracias por tus increíbles aportes. Podrías ayudarme con este error:
KeyError Traceback (most recent call last)
in
—-> 1 accuracy = sport_train.history[‘acc’]
2 val_accuracy = sport_train.history[‘val_acc’]
3 loss = sport_train.history[‘loss’]
4 val_loss = sport_train.history[‘val_loss’]
5 epochs = range(len(accuracy))
KeyError: ‘acc’
Gracias 😀
Hola Jean, creo que debe ser un fallo de tipeo, donde debería poner “accuracy” (en vez de acc).
Saludos y gracias por escribir!
Exactamente ese era el error. Muchas gracias
Hola amigo, excelente tutorial, pero tengo una pregunta.
Como ejecuto la red neuronal ya entrenada desde otro archivo, pasándole un nuevo archivo de prueba para que valide?
Gracias.
Hola Victor, si vas a la Jupyter Notebook en GitHub del artículo, verás que muestra cómo guardar la red neuronal (en un archivo h5py) y luego la usa para hacer predicción de “nuevas imágenes”.
Saludos,
me sale este error, a que se debe ayudeme porfavor.
28
29 dircount = dircount[1:]
—> 30 dircount[0]=dircount[0]+1
31 print(‘Directorios leidos:’,len(directories))
32 print(“Imagenes en cada directorio”, dircount)
IndexError: list index out of range
Hola, estoy intentado realizar este ejercicio con solo dos directorios en vez de 10.
Me aparece el siguiente error:
ValueError: setting an array element with a sequence. The requested array has an inhomogeneous shape after 1 dimensions. The detected shape was (47,) + inhomogeneous part.
debido a la línea:
X = np.array(images, dtype=np.uint8) #convierto de lista a numpy
¿Cómo puedo solucionarlo?
Hola Elena, Si puedes escríbeme desde el formulario de contacto explicando el error e intento solucionarlo. Un Saludo
Hola, lograste solucionar el error?
Buenas, saludos.
muy interesante el articulo publicado, para una persona que se inicia en estos temas es bastante acogedor, sin embargo me atreveria a preguntarle, para la tecnica de validacion por matriz de confusion, que es lo que deberia tomar en cuenta?.
gracias y saludos de antemano.
Hola Juan Ignacio
Mi primera vez con este lio, y me parce «acojo…nante» tu trabajo, GRACIAS
Pero necesito que me digas como puedo probar una imagen cualquiera contra el modelo… soy encapad.
Soy un COMPLETO ignorante en esto y me he decidido a «copiar» este ejemplo y tratar de entenderlo con posterioridad…
GRACIAS