
El modelo de Machine Learning llamado Stable Diffusion es Open Source y permite generar cualquier imagen a partir de un texto, por más loca que sea, desde el sofá de tu casa!

Estamos viviendo unos días realmente emocionantes en el campo de la inteligencia artificial, en apenas meses, hemos pasado de tener modelos enormes y de pago en manos de unas pocas corporaciones a poder desplegar un modelo en tu propio ordenador y lograr los mismos -increíbles- resultados de manera gratuita. Es decir, ahora mismo, está al alcance de prácticamente cualquier persona la capacidad de utilizar esta potentísima herramienta y crear imágenes en segundos (ó minutos) y a coste cero.
En este artículo les comentaré qué es Stable Diffusion y por qué es un hito en la historia de la Inteligencia Artificial, veremos cómo funciona y tienes la oportunidad de probarlo en la nube o de instalarlo en tu propio ordenador sea Windows, Linux ó Mac, con o sin placa GPU.
Reseña de los acontecimientos
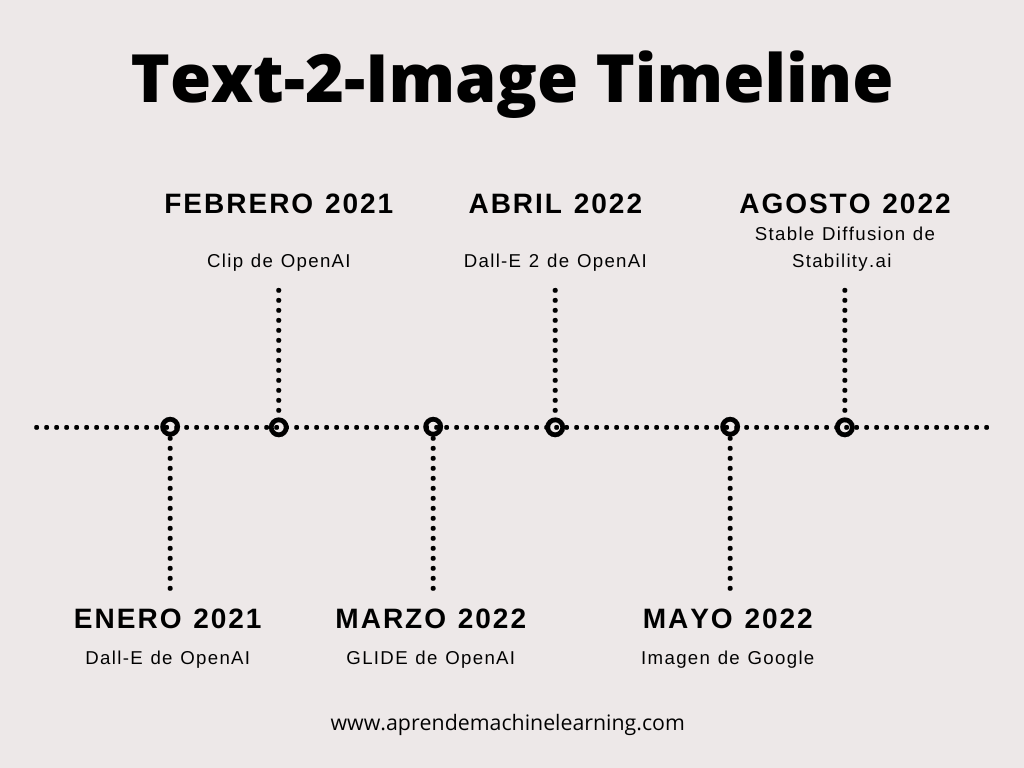
- 2015: Paper que propone los Diffusion Models.
- 2018 -2019 Text to Image Synthesis – usando GANS se generan imágenes de 64×64 pixels, utiliza muchos recursos y baja calidad de resultados.
- Enero 2021: Open AI anuncia Dall-E, genera imágenes interesantes, pequeñas, baja resolución, lentas.
- Febrero 2021: CLIP de Open AI (Contrastive Language-Image Pretraining), un codificador dual de lenguaje-imagen muy potente.
- Julio 2021: Image Text Contrastive Learning Mejora sobre las Gans “image-text-label” space.
- Marzo 2022: GLIDE: esta red es una mejora sobre Dall-E, tambien de openAI pero usando DIFFUSION model.
- Abril 2022: Dall-E 2 de Open AI, un modelo muy bueno de generación de imágenes. Código cerrado, acceso por pedido y de pago.
- Mayo 2022: Imagen de Google.
- Agosto de 2022: Lanzamiento de Stable Diffusion 1.4 de Stability AI al público. Open Source, de bajos recursos, para poder ejecutar en cualquier ordenador.
¿Qué es Stable Diffusion?

Stable Diffusion es el nombre de un nuevo modelo de Machine Learning de Texto-a-Imagen creado por Stability Ai, Comp Vis y LAION. Entrenado con +5 mil millones de imágenes del dataset Laion-5B en tamaño 512 por 512 pixeles. Su código fue liberado al público el 22 de Agosto de 2022 y en un archivo de 4GB con los pesos entrenados de una red neuronal que podemos descargar desde HuggingFace, tienes el poder de crear imágenes muy diversas a partir de una entrada de texto.
Stable Diffusion es también una gran revolución en nuestra sociedad porque trae consigo diversas polémicas; al ofrecer esta herramienta a un amplio público, permite generar imágenes de fantasía de paisajes, personas, productos… ¿cómo afecta esto a los derechos de autor? Qué pasa con las imágenes inadecuadas u ofensivas? Qué pasa con el sesgo de género? Puede suplantar a un diseñador gráfico? Hay un abanico enorme de incógnitas sobre cómo será utilizada esta herramienta y la disrupción que supone. A mí personalmente me impresiona por el progreso tecnológico, por lo potente que es, los magnificos resultados que puede alcanzar y todo lo positivo que puede acarrear.
¿Por qué tanto revuelo? ¿Es como una gran Base de datos de imágenes? – ¡No!
Es cierto que fue entrenada con más de 5 mil millones de imágenes. Entonces podemos pensar: “Si el modelo vio 100.000 imágenes de caballos, aprenderá a dibujar caballos. Si vio 100.000 imágenes de la luna, sabrá pintar la luna. Y si aprendió de miles de imágenes de astronautas, sabrá pintar astronautas“. Pero si le pedimos que pinte “un astronauta a caballo en la luna” ¿qué pasa? La respuesta es que el modelo que jamás había visto una imagen así, es capaz de generar cientos de variantes de imágenes que cumplen con lo solicitado… esto ya empieza a ser increíble. Podemos pensar: “Bueno, estará haciendo un collage, usando un caballo que ya vio, un astronauta (que ya vió) y la luna y hacer una composición“. Y no; no es eso lo que hace, ahí se vuelve interesante: el modelo de ML parte de un “lienzo en blanco” (en realidad es una imagen llena de ruido) y a partir de ellos empieza a generar la imagen, iterando y refinando su objetivo, pero trabajando a nivel de pixel (por lo cual no está haciendo copy-paste). Si creyéramos que es una gran base de datos, les aseguro que no caben las 5.500.000.000 de imágenes en 4 Gygabytes -que son los pesos del modelo de la red- pues estaría almacenando cada imagen (de 512x512px) en menos de 1 Byte, algo imposible.
¿Cómo funciona Stable Diffusion?
Veamos cómo funciona Stable Diffusion!
Stable Diffusion está basado en otro modelo llamado “Latent Diffusion” que proviene de modelos de difusión de ML que están entrenados para “eliminar el ruido de “imágenes sucias” paso a paso”. Esto quiere decir que al modelo le entrenamos con fotos donde ensuciamos ciertos pixeles, con manchas, desenfoque (blur) o distorsiones que agregamos a propósito y le pedimos como salida la imagen correcta (la imagen original sin ruido). Entonces, la red neuronal del modelo aprende a “quitar el ruido”, es decir, transformar esas manchas (ruido) en la imagen original.
Los modelos de difusión lograron resultados muy buenos como generadores de imágenes aunque su contra es que como trabajan a nivel de pixel requieren de mucha memoria RAM y toman tiempo para crear imágenes de alta definición.
La mejora introducida por los modelos “Latent Diffusion” es que el modelo es entrenado para generar “representaciones de imágenes latentes” (comprimidas). Sus tres componente principales son:
- Autoencoder (VAE)
- U-Net
- Text-Encoder
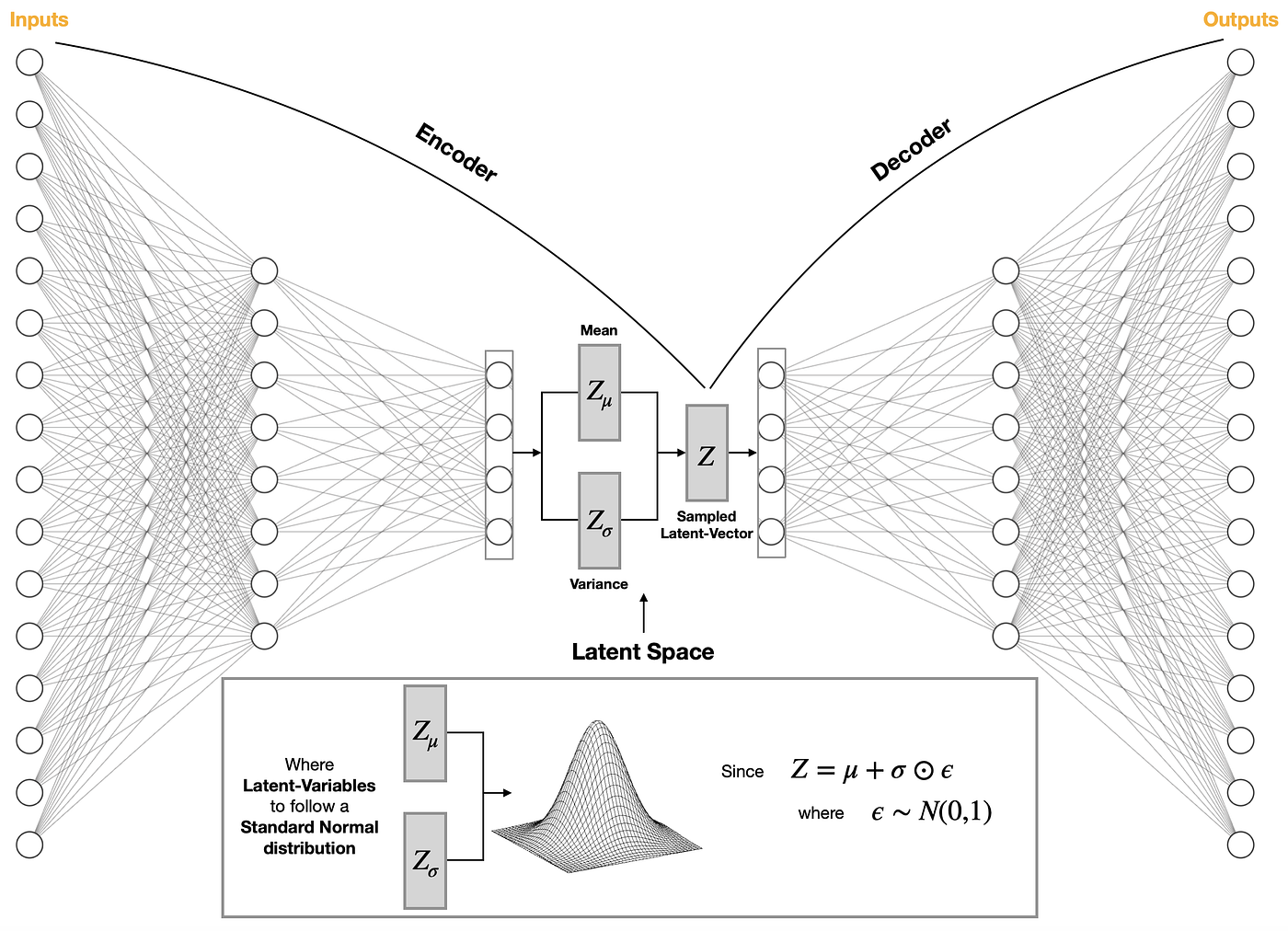
1-Autoencoder (VAE)
El modelo VAE tiene dos partes, un codificador y un decodificador. En codificador es usado para convertir la imagen en una representación latente de baja dimensión, que servirá como entrada a la “U-Net”. El decodificador por el contrario, transforma la representación latente nuevamente en una imagen.
Durante el entrenamiento de difusión latente, se usa el codificador para obtener las representaciones latentes de las imágenes para el proceso de difusión directa, se aplica más y más ruido en cada paso. Durante la inferencia, se realiza el proceso inverso de difusión donde “expande los latentes” para convertirlos nuevamente en imágenes con el decodificador VAE. Para la inferencia sólo necesitamos el decodificador.
2-U-Net
La U-Net tiene una mitad de camino “de contracción” y otra mitad de “expansión“, ambos compuestos por bloques ResNet (para soportar redes profundas sin desvanecer el aprendizaje). La primera mitad de la U-Net reduce la imagen a una representación de baja resolución (similar a un encoder) y la segunda parte intentará generar la imagen original en alta resolución (similar a un decoder). La salida de la U-Net predice el “ruido residual” que puede ser usado para calcular la representación “sin ruido” de la imagen.
Para prevenir que la U-Net pierda información importante durante el downsampling, se agregan conexiones de “atajo corto” (skip connections) entre los dos caminos: encoder y decoder. Además la U-Net de stable diffusion puede condicionar su salida respecto de los text-embeddings de las capas de cross-attention. Las capas de “Atención Cruzada” se agregan tanto en las partes de codificación y decodificación de la U-Net, entre los bloques ResNet. A eso se le llama Difusión guiada ó Difusión condicionada.

3-Text-Encoder
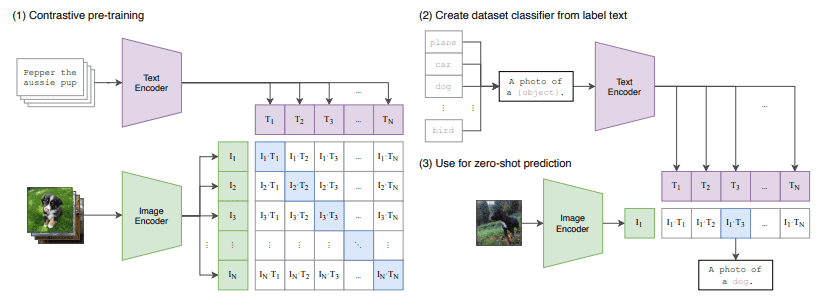
El Text-Encoder es el responsable de transformar el mensaje de entrada por ejemplo “Ilustración de Taylor Swift con un pingüino bailando en la ciudad” en un espacio de embeddings que puede ser comprendido por la U-Net. Se utiliza un encoder de tipo Transformers que mapea la secuencia de palabras de entrada en una secuencia latente del embedding de textos.
Stable Diffusion no entrena al Text-Encoder durante la etapa de entrenamiento del modelo si no que utiliza un encoder ya entrenado de CLIP.

Resumen de la arquitectura de Stable Difussion
El modelo al completo, como lo muestra la web oficial de Stable Diffusion es así:
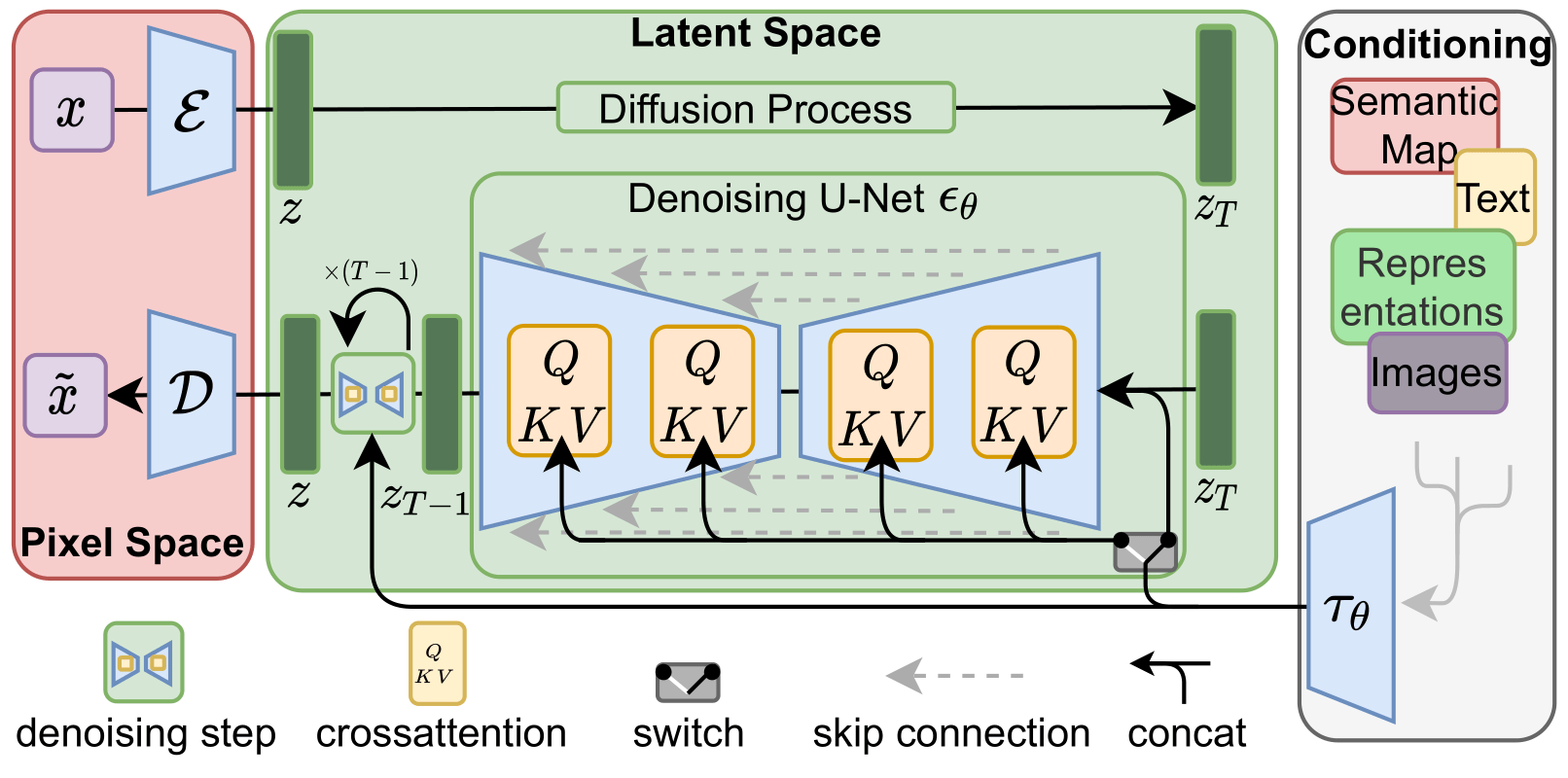
Al momento de entrenar, la red tiene como entrada una imagen y un texto asociado. La red convertirá la imagen “en ruido” por completo y luego la intentará reconstruir. No olvidemos que es un problema de Aprendizaje supervisado, por lo cual, contamos con el dataset completo, con F(x)=Y desde el inicio.
- A la izquierda, en rojo “Pixel Space” tenemos la “x” inicial que entrará en el Encoder de la VAE.
- En verde, Espacio Latente, Arriba el Proceso de Difusión, lleva “z” a “zT” agregando ruido a la imagen
- En verde, Espacio Latente, Abajo, de derecha a izquierda, entra “zT” a la U-Net e intentará reconvertirla en “z”.
- Conditioning, a la derecha, utiliza el modelo CLIP con el texto asociado a la imagen y dirige la salida de la U-Net.
- Por último, luego de iterar varias veces la U-Net y obtener una “z buena” (que es la imagen en estado latente), la decodificamos a pixeles utilizando el Decoder de la VAE (en el Pixel Space) y obtendremos una imagen similar a la “x” inicial.
Esta es la arquitectura para entrenar al modelo. Si vas a utilizar la red una vez entrenada, realmente realizaremos el “camino de inferencia“, veamos:
Al hacer la Inferencia, creamos una imagen:
Al momento de hacer la inferencia crearemos una imágen desde ruido! Por eso, el primer paso, es crear una imagen de 512×512 completamente de pixeles aleatorios!
Veamos la gráfica de inferencia que nos propone Stability.ai

Entonces, generamos la imagen de ruido y a partir de ella, la pasaremos a la U-Net que junto con el texto de entrada irá condicionando la salida, una y otra vez, intentará “quitar el ruido” para volver a una imagen original inexistente…
¿Te das cuenta? estamos engañando a la red neuronal, para que genere un gráfico que nunca antes existió…

La pobre Red Neuronal, es como si fuera un escultor con un cincel al que le damos un bloque de piedra enorme y le decimos “Quiero a Taylor Swift con un pingüino, hazlo!“.
Entonces, en cada iteración, creará desde el ruido, una imagen
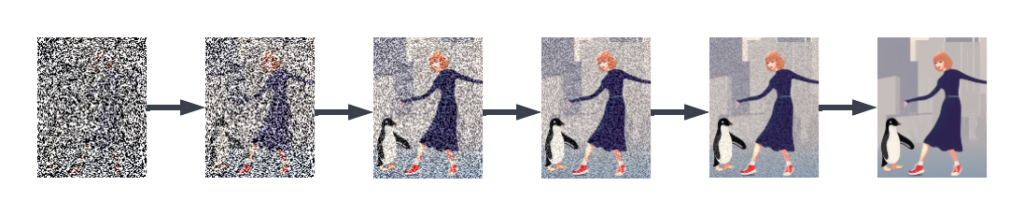
Pero… ¿Qué imágenes puedes crear con Stable Diffusion?
Veamos algunos ejemplos de imágenes creadas por Stable Diffusion para ver si te convenzo de que esto es realmente algo grande… y luego ya puedes decidir si quieres probarlo y hasta instalarlo en tu propio equipo.
Aquí algunas imágenes encontradas en diversos canales:
En Lexica, que por cierto, te recomiendo visitar su web, pues tiene imágenes junto a los prompts para generarlas.
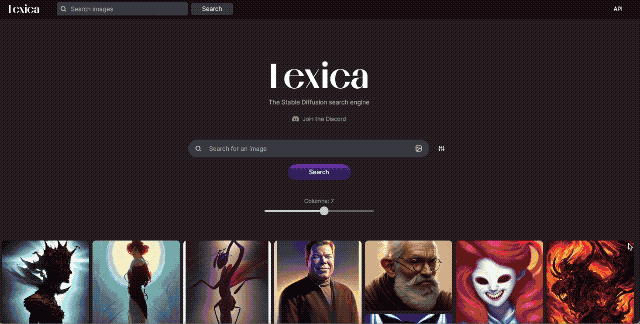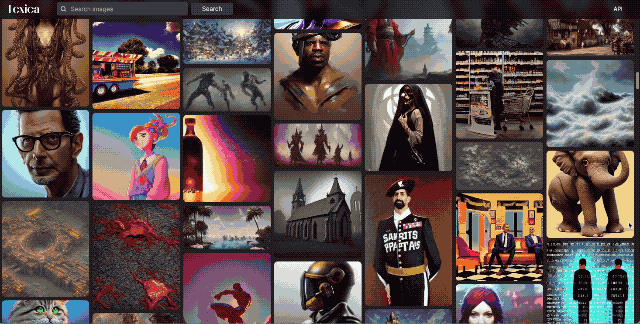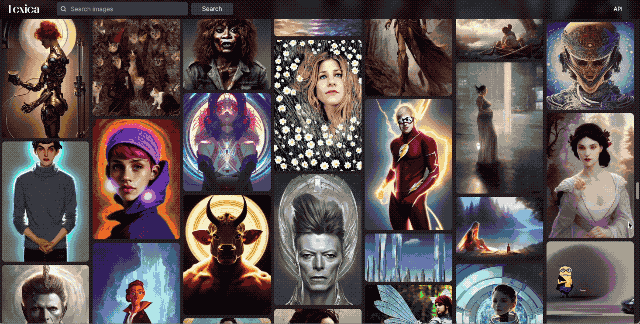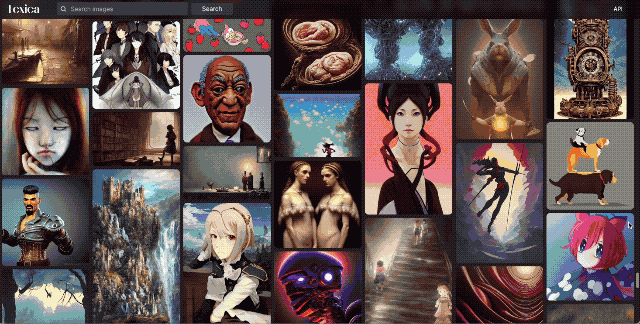
En Instagram






Imágenes encontradas en Reddit




Imágenes encontradas en Twitter




¡Quiero usar Stable Diffusion! ¿Cómo hago?
Puedes pagar por el servicio, ejecutar en la nube ó instalarlo en tu propia computadora.
1-Probarlo gratis, lo primero! (pagar luego…)
Desde la web de los creadores puedes dar tus primeros pasos. Tienes que registrarte y obtienes unos créditos gratuitos, luego que se acaben, tendrás que pagar. Debes entrar en https://beta.dreamstudio.ai/dream
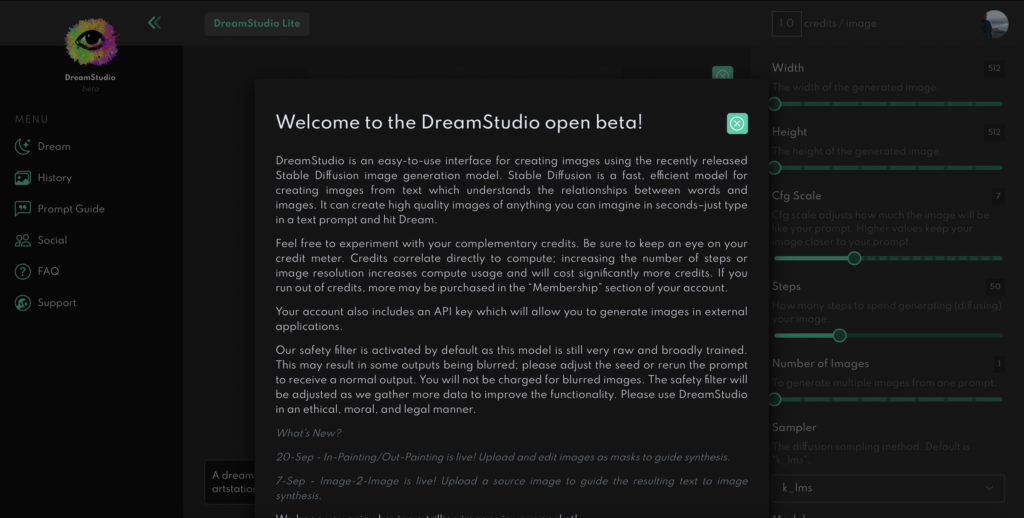
Veremos en la parte de abajo, centro la caja de texto donde podemos ingresar el “prompt” con lo que queremos dibujar. Sobre la derecha los parámetros de configuración, que comentaremos luego, pero lo básico es que puedes elegir el tamaño de imagen y cantidad de imágenes a generar.
Ten en cuenta que tienes unos créditos (gratuitos) limitados para utilizar, por lo que debes estar atento a lo que vas consumiendo.
2-Instalar StableDiffusion en tu Computadora
Podemos instalar Stable Difussion en Windows y en Linux con “Instaladores automáticos” siguiendo las instrucciones del repositorio de Automatic1111. Para Windows hay otro instalador aqui .
Puedes instalar en ordenadores Mac (y aprovechar las GPUS de los chips M1 y M2) desde el repositorio de InvokeAI siguiendo las instrucciones para Macintosh.
Si te atreves a instalarlo de manera un poco más “manual”, puedes aventurarte a seguir las instrucciones del Repositorio Oficial de Stable Diffusion. No es difícil, básicamente, si tienes instalado Anaconda en tu ordenador, es clonar el repo y crear el environment de python siguiendo los pasos.
Un paso Clave: descargar el modelo de la red de HuggingFace
Casi todos los modos de instalar que vimos anteriormente, necesitan de un paso manual que es el de obtener y descargar el modelo desde la web de HuggingFace que ocupa 4.27 Gygabytes. Para ello, debes registrarte en HuggingFace e ir a la página del modelo. Deberás aceptar las condiciones de uso, y luego podrás descargar el último modelo, al momento de escribir este artículo es el archivo sd-v1-4.ckpt. Una vez descargado, lo deberás copiar en la carpeta models/ldm/stable-diffusion-1/ y renombrar el archivo como model.ckpt.
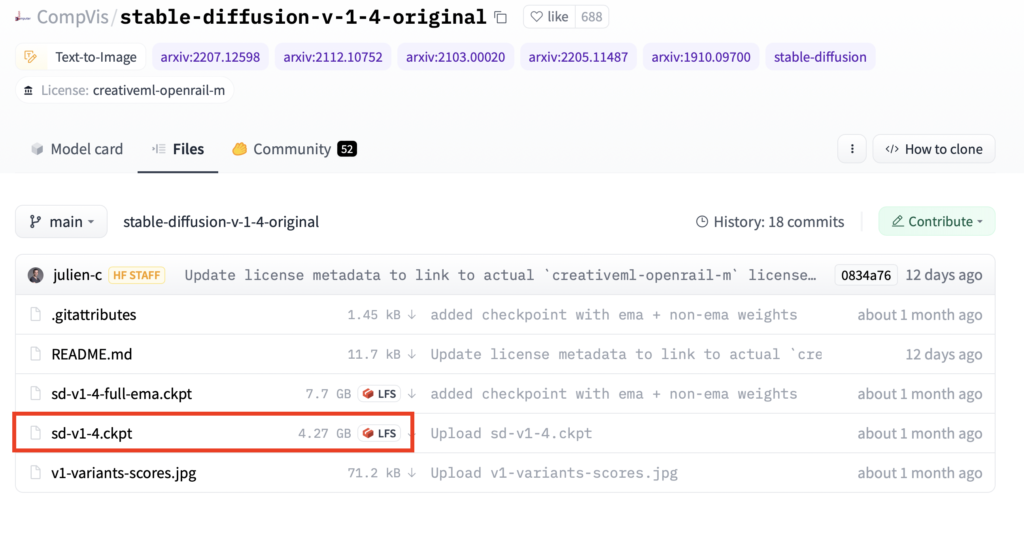
Eso es todo! Voilá, crea todas las imágenes que quieras! Tienes el mundo en tus manos!
Tiempos de “Rendering”
Si tienes una tarjeta gráfica con GPU, en mi caso la Nvidia RTX3080 tarda 5 segundos en crear una imágen de 512x512px. Si no tienes tarjeta puedes crear imágenes usando CPU pero tardarán unos 6 minutos (en un ordenador del año 2015 Core i5 y 8GB de memoria). En ordenadores Macbook con chip M2 tarda aproximadamente 1 minuto por imagen.
3-Usar StableDiffusion gratis y con GPU desde la nube de Google Colab
Otra opción para utilizar este genial modelo de forma gratuita es utilizar las notebooks de Google Colab y activar la opción de GPU. Existen varias notebooks compartidas que puedes utilizar como template con la instalación, aquí te recomiendo esta notebook y un hilo en Twitter en español, que te ayuda a seguir los pasos.
Entendiendo los parámetros de entrada de Stable Diffusion
Tanto en la versión web, la de instaladores, manual ó en la nube; contaremos con los mismos parámetros para configurar la red neuronal. Estos son:
- Alto y Ancho de imagen: deben ser múltiplos de 64, tamaño mínimo de 256 y máximo de 1024px. Sin embargo la recomendación es utilizar 512×512 pues es el tamaño con el que se entrenó la red.
- Steps: es la cantidad de iteraciones que realizará la U-Net durante la inferencia. Cuanto más iteramos, mayor “ruido” quitaremos de la imagen, es decir, quedará mejor definida. Pero también tardará más tiempo. Teniendo en cuenta el sampler que utilicemos, un valor de entre 25 y 50 estará bien.
- CFG Scale: este es un valor curioso, pues determina el “grado de libertad” que damos a la propia red para ser creativa. El valor por defecto es 7.5. Si disminuimos el valor, se centrará más en nuestro Prompt. Si aumentamos el valor (más de 10) empezará a improvisar y a hacer dibujos más delirantes y más a su antojo.
- Número de Imágenes: la cantidad de diversas imágenes que se crearán durante la inferencia. Cuantas más creamos más memoria RAM necesitaremos, tener en cuenta.
- Sampler: será la función con la que se creará el “denoising” en la U-Net y tiene implicancias en la imagen que se generará. El Sampler más avanzado (de momento) es el DPM2 y necesita más steps para lograr buenos resultados, llevando más tiempo. Curiosamente, el sampler llamado Euler Ancestral es el más básico y logra muy buenas imágenes en unas 20 iteraciones (menor tiempo).
- Seed ó Semilla: La semilla está relacionada con la imagen con ruido que generamos inicialmente desde donde la red empezará a dibujar. Con una misma semilla podremos replicar una imagen todas la veces que queramos para un mismo prompt. Si no asignamos un valor de semilla, se generará aleatoriamente, obteniendo siempre imágenes distintas para el mismo prompt.
El Prompt Engineering
Se le llama Prompt Engineering al arte de introducir textos que generen buenas imágenes. Lo cierto es que no es tan fácil como parece la creación de imágenes, es decir, la red siempre creará imágenes, pero para que destaquen realmente, hay que agregar las keywords adecuadas. Por suerte ya hay personas que descubrieron muchos de esos tweaks
Los truquillos en el Prompt
Varios exploradores recomiendan seguir una fórmula de tipo:
Tipo imagen – objeto – lugar – tiempo – estilo ó autor
Por ejemplo:
Pintura de un gato con gafas en un teatro, 1960, por Velazquez
Y esto mismo… pero en inglés, obtenemos:

Hay algunas palabras que se agregan al final, que son muy útiles, poner “trending on ArtStation”, “highly detailed”, “unreal engine 5”.
Aqui te dejo un enlace a un artículo maravilloso que muestra con ejemplo de muchas de las combinaciones.

imágenes generadas con Imágenes: “img2Img”
Además del txt2Img (que a partir de un texto, generemos una imagen), tenemos otra opción llamada img2img.
Con esta opción ingresamos una imagen creada por nosotros con el “paintbrush” u otra herramienta similar y la utilizaremos como imagen de inicio para generar una nueva imagen. Esto tiene mucha lógica si lo piensas, en vez de empezar con una imagen llena de ruido, le damos unas “guías” a la red neuronal para que pueda crear la imagen. Y los resultados son increíbles!


Por si fuera poco, Inpainting y Outpainting
El Inpainting permite crear una máscara dentro de una imagen y que el modelo dibuje dentro, manteniendo el estilo pictórico y la coherencia.
También existe el llamado OutPainting, que nos permite “extender” una imagen, logrando obras increíbles, será mejor que lo veas!
Resumen y Conclusiones
A estas alturas, espero que estes tan emocionado como yo con esta nueva tecnología y esto es sólo el comienzo! Los modelos de Machine Learning de texto-a-imagen acaban de aterrizar y se perfeccionarán; uno de los puntos fuertes y gran acierto de Stable Diffusion es que al lanzarse a todo el público, logró captar a una gran comunidad de desarrolladores, artistas y curiosos que colaboran y que potencian sus capacidades aún más! Al momento de escribir el artículo, han pasado menos de 2 meses y aparecieron muchísimos proyectos relacionados. Además se comenta que está por aparecer la nueva versión del modelo de pesos entrenado 1.5 dentro de poco. Algunos usuarios hasta crearon videos mediante Stable Diffusion y otros empiezan a mezclar la red con las 3 dimensiones para crear objetos.
En próximos artículos veremos en mayor profundidad y en código Python el uso de redes VAE, U-Net y Transformers.
Hasta pronto!
Material Adicional:
Aquí comparto dos videos muy buenos sobre Arte con IA y otro sobre Stable Diffusion
Otros artículos relacionados de interés:
Suscripción al Blog
Recibe los próximos artículos sobre Machine Learning, estrategias, teoría y código Python en tu casilla de correo!
NOTA: algunos usuarios reportaron que el email de confirmación y/o posteriores a la suscripción entraron en su carpeta de SPAM. Te sugiero que revises y recomiendo que agregues nuestro remitente info @ aprendemachinelearning.com a tus contactos para evitar problemas. Gracias!
El libro del Blog
Si te gustan los contenidos del blog y quieres darme una mano, puedes comprar el libro en papel, ó en digital.