
Luego de haber hecho un ejercicio Práctico de Detección de objetos en imágenes por medio de redes neuronales, veremos la teoría que hay detrás de estos algoritmos.
Para comprender el artículo doy por sentado que ya tienes conocimiento de cómo funcionan las redes neuronales y de la teoría de Clasificación de imágenes. Si no, te recomiendo que leas primero esos artículos.
Agenda
- Introducción: ¿Qué es la detección de imágenes?
- Primera intuición de detección a partir de la clasificación con CNN
- R-CNN: búsqueda selectiva
- ¿Cómo funciona R-Cnn?
- Problemas y mejoras: fast y faster r-cnn
- Detección Rápida: YOLO
- ¿Cómo funciona YOLO?
- Arquitectura de la red Darknet
- Otras alternativas
- 2016 – Single Shot Detection
- 2018 – RetinaNet
- 2019 – Google Spinet
- 2020 – Facebook saca del horno DETR
- Resumen

Introducción: ¿Qué es la detección de imágenes?
Podemos tener la errónea intuición de que la detección de imágenes sea una tarea sencilla, pero veremos que realmente no lo es y de hecho es un gran problema a resolver. Nosotros los humanos podemos ver una foto y reconocer inmediatamente cualquier objeto que contenga de un vistazo rápido, si hay objetos pequeños o grandes, si la foto es oscura ó hasta algo borrosa. Imaginemos un niño escondido detrás de un árbol donde apenas sobresale un poco su cabeza ó un pie.
Para la detección de imágenes mediante Algoritmos de Machine Learning esto implica una red neuronal convolucional que detecte una cantidad limitada (ó específica) de objetos, no pudiendo detectar objetos que antes no hubiera visto, ó si están en tamaños que logra discernir y todas las dificultades de posibles “focos”, rotación del objeto, sombras y poder determinar en qué posición -dentro de la imagen- se encuentra.
Si es difícil con 1 objeto… imagínate con muchos!.
¿En qué consiste la detección de objetos?
Un algoritmo de Machine Learning de detección, para considerarse como tal deberá:
- Detectar multiples objetos.
- dar la posición X e Y del objeto en la imagen (o su centro) y dibujar un rectángulo a su alrededor.
- Otra alternativa es la segmentación de imágenes (no profundizaremos en este artículo).
- Detectar “a tiempo”… o puede que no sirva el resultado. Esta es una característica que debemos tener en cuenta si por ejemplo queremos hacer detección en tiempo real sobre video.
Nueva Salida
Entonces para entrenar nuestra máquina de manera supervisada deberemos indicar la clase del objeto (por ejemplo perro ó gato) y además la posición dentro de la imagen, X, Y el ancho y alto del objeto.
Y por si esto fuera poco, podrían ser múltiples objetos en la misma imagen, con lo cual para detectar 2 perros en una foto, necesitamos como salida 10 neuronas.
Este es un gran cambio, pues en clasificación de imágenes veníamos acostumbrados a devolver un array con por ejemplo Perro = [1 0] y Gato = [0 1].
La nueva salida deberá contener adicionalmente la posición (por ej. 54,45) y dimensión (por ej. 100,100) de cada clase, resultando en algo mínimo como
- [1 0 100 100 54 45] pudiendo detectar sólo 1 objeto ó
- [1 0 100 100 54 45 0 1 200 200 30 25] para 2 objetos.
Primera intuición: detección a partir de la clasificación
Podemos partir de este punto: tenemos una red CNN entrenada para detectar perros y gatos y supongamos que tiene una muy buena taza de aciertos. A esta red le pasamos una imagen nueva y nos devuelve “perro” ó “gato”. Agregaremos una tercera salida “otros” por si le pasamos la foto de algo que no sepa reconocer .
Entre las redes CNN pre-entregadas más conocidas están Alexnet, Resnet, y VGG
Si a nuestra red pre-entrenada, le pasamos una imagen con 2 perros será incapaz de detectarlos, puede que no detecte ni siquiera a uno.
Si le pasamos una imagen con perros y gatos, tampoco los podrá identificar y mucho menos localizar.
Entonces lo que el “sentido común de ingenieros” nos dice es: “vamos a iterar”. Es decir, iteremos un “área reducida” dentro de la foto de izquierda a derecha y de arriba abajo y le aplicamos la CNN pre-entrenada para ver si detecta algo.
Al ir iterando, lograremos detectar los 2 animales de la foto.











Sin embargo esta solución trae consigo múltiples inconvenientes:
- ¿De qué tamaño será la ventana deslizante? y de hecho, podría ser de diversos tamaños.
- ¿Cuántos píxeles nos moveremos hacia izquierda (y luego hacia abajo)?
- Dependiendo de esos factores, el tiempo de cómputo podría ser muy largo, pues para cada movimiento implica realizar una clasificación individual con la CNN.
- Si detectamos algún objeto dentro de la ventana, ¿quiere decir que tengo los valores x e y? No necesariamente.
- Si nos movemos apenas pixeles con la ventana, podemos estar detectando al “mismo perro” múltiples veces
- Surge una problemática de poder distinguir entre animales si estos se encuentran muy cercanos.



De los puntos 5 y 6 surge la necesidad de crear una nueva métrica específica para la detección de imágenes en donde podamos evaluar al mismo tiempo si la clase de objeto es correcta y si la posición del “bounding box” (X,Y, alto y ancho) es buena. Esa métrica será “mAP“.

A raíz de estos puntos, surgen estrategias para intentar solventarlos. Veamos algunas.
R-CNN: búsqueda selectiva
En 2014 surgen las “Region Based Convolutional Neural Networks” con la siguiente propuesta: primero determinar “regiones de interés” dentro de la imagen (esto es conocido como “selective search”) y luego realizar clasificación de imágenes sobre esas áreas usando una red pre-entrenada.
Esto implica un primer algoritmo sobre la imágen que pueda determinar las áreas de interés que pueden llegar a ser 2000 regiones de diversos tamaños (si había más, se descartan). Luego pasar esas regiones por la CNN y mediante un clasificador binario validar si eran de clases correctas y eliminar las de poca confianza. Finalmente un regresor se encargaría de ajustar correctamente la posición de la localización.
La selección de las regiones podría ser por ejemplo “áreas contiguas con un mismo tono de color” ó detección de líneas que delimiten áreas, ó cambios bruscos en contraste y brillo. Son pasadas “rápidas” sobre una imagen, similar a como lo hace un editor de imágenes.

Para evitar el solapamiento del mismo objeto en diversas áreas se utiliza el concepto de IoU ó “Intersection over Union”.
IoU: nos da un porcentaje de acierto del área de predicción frente a la bounding-box real que queríamos detectar.
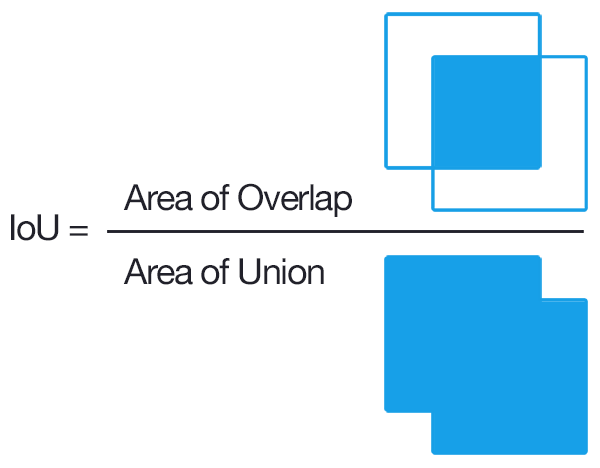
El IoU en conjunto con “Non-Máximum-Supression” ayudan a seleccionar las áreas del objeto que queremos localizar.
NMS: nos permite quedarnos de entre muchas cajas que detectaron al mismo objeto y se superponen, con la que mejor se ajusta al resultado. Nos quedamos con la mejor y eliminamos al resto.

A pesar de todas estas mejoras, la detección de objetos sobre una sola imagen podía tomar unas 25 segundos. Y el entrenamiento de la propia red es muy lento.
Mejoras sobre R-CNN: fast y faster R-cnn
Surgen otros 2 algoritmos: fast R-CNN y luego faster R-CNN para intentar mejorar el tiempo de detección.
Fast R-CNN mejora el algoritmo inicial haciendo reutilización de algunos recursos como el de las features extraídas por la CNN agilizando el entreno y detección de las imágenes. Esta nueva red tiene mejoras también en el IOU y en la función de Loss para mejorar el posicionamiento de la “caja delimitante”. Sin embargo no ofrece un aumento dramático de velocidad en el entrenamiento y detección.
Faster R-CNN logra una mejora en velocidad al integrar el algoritmo de “región proposal” sobre la propia CNN. Además aparece el concepto de usar “anchor” fijos, es decir, ciertos tamaños pre calculados para la detección de objetos específicos de la red. Por ejemplo, podemos definir 3 tamaños de ventana en 3 escalas distintas de tamaños, es decir un total de 9 anclas.
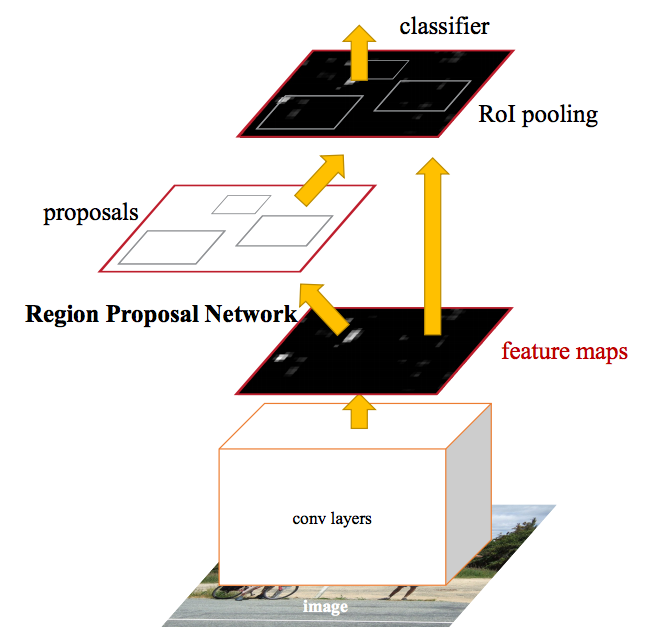
Mask R-CNN
No entraré en detalle, esta red, intenta hacer uso de las R-CNN pero en vez de detectar el “bounding box” de cada objeto, intentará hacer segmentación de imagen, definiendo la superficie de cada objeto.

Detección Rápida: YOLO
En 2016 crean YOLO, una red que quiere decir “You Only Look Once“. Esta red hace una única pasada a la red convolucional y detecta todos los objetos para los que ha sido entrenada para clasificar. Al ser un “sólo cálculo” y sin necesidad de iterar, logra velocidades nunca antes alcanzadas con ordenadores que no tienen que ser tan potentes. Esto permite detección sobre video en tiempo real de cientos de objetos en simultáneo y hasta su ejecución en dispositivos móviles.
¿Cómo funciona YOLO ?
Yolo es una solución que reutiliza varias técnicas que vimos anteriormente con un “twist-plot” final.
Yolo define una grilla de tamaño fijo sobre la imagen de 13×13. Sobre esas celdas intentará detectar objetos valiéndose de anchors fijos, por ejemplo de 3 anclas con 3 tamaños distintos (9 predicciones por cada celda). Hace uso de IoU y Non-Max-supression. También tiene asociada una red de regresión al final para las posiciones de los bounding-boxes.


La “grandiosidad” de YOLO consiste en su red CNN. Antes vimos que R-CNN utilizaba algún algoritmo adicional para seleccionar las regiones de interés sobre las que realiza las predicciones. En cambio YOLO, utiliza la misma Red CNN de clasificación con un “truco” por el cual no necesita iterar la grilla de 13×13, si no que la propia red se comporta como si hiciera un especie de “offset” que le permite hacer la detección en simultáneo de las 169 casillas.
YOLO utiliza una red CNN llamada Darknet, aunque también puede ser entrenada con cualquier otra red Convolucional. Al mismo tiempo de entrenarse se crea la red con este <<offset>> que comentaba.
Además Yolo utiliza las neuronas de tipo convolucional al final de la cadena sin necesidad de hacer la transformación a una red “tradicional”.
Gracias a estos retoques, logra la sorprendente capacidad de casi 60 FPS (cuadros por segundo) en ordenadores normales. Se le critica que si bien es rápida, suele tener menor porcentaje de aciertos frente a las R-CNN.

Pero con el paso del tiempo fueron evolucionando las versiones YoloV2, V3 y recientemente V4 que están enfocadas a mejorar esa precisión de las bounding boxes, a la vez que mantienen su rapidez.

Arquitectura de la Red
La arquitectura se basa en una red convolucional GoogleNet y consta de 24 capas convolucionales. El autor la bautizó como Darknet. Embebe en su salida tanto la parte que clasifica las imágenes como la de posicionamiento y tamaño de los objetos.

Por ejemplo par el CocoDataset que debe detectar 80 objetos diferentes, tendremos como salida:
| Tamaño de grilla | Cantidad Anclas | Cantidad de clases | Ccore, X, Y, Alto, Ancho |
| 13 * 13 | * 3 * | (80 + | * 5) |
Para este ejemplo nos dará un array de 43.095 datos siendo el máximo de objetos que puede detectar y localizar 13x13x3 = 507 objetos de 80 clases en la misma foto en una sola pasada. (Realmente hará 13x13x3 x3 tamaños = 1521 predicciones). Sorprendente!.
Crea tu propia red de detección de objetos YOLO siguiendo este ejercicio explicado paso a paso y con todo el código Python en una Jupyter Notebook usando Keras y Tensorflow
Otras Alternativas para Detección
Comentaremos brevemente otras técnicas que surgieron y que también se pueden utilizar.
SSD – Single Shot Detector
Tiene una estructura piramidal en su CNN en la que las capas van disminuyendo gradualmente. Esto le permite poder detectar objetos grandes y pequeños. No utiliza una grilla predefinida, pero cuenta con “anclas” de distintas proporciones que se van escalando a medida que descendemos por la pirámide (mapa de features más pequeños, con anclas proporcionalmente más grandes).

RetinaNet (2018)
RetinaNet también se basa en una estructura de CNN piramidal mejorada para reconocer objetos de diversos tamaños en una sola pasada. Innova con una nueva función de pérdida llamada <<Focal Loss>>.

Google: Spinet (dic 2019)
Google Spinet rompe con la estructura piramidal y propone una arquitectura novedosa llamada “scale-permuted” en la que se alternan diversos tamaños en las convoluciones.

Facebook: DETR (junio 2020)
Facebook propone una “End to End object detection with Transformers“. Es decir, utilizar la más novedosa y efectiva técnica de redes neuronales utilizada en NLP pero aplicada a la detección de imágenes! Muy ingenioso!

Resumen
La tarea de Detección de objetos en imágenes fue impulsora de mejora tanto en redes neuronales convolucionales como en la arquitectura general utilizada poniendo a prueba el valor real del deeplearning, entrelazando redes con funciones específicas.
Los logros obtenidos son enormes, de gran aplicación y como vemos sigue siendo un campo en desarrollo, en donde grandes como Google y Facebook siguen innovando con nuevas propuestas, aún con un mundo bajo Pandemia.
Las aplicaciones que tiene la detección de imágenes van desde seguridad, conducción de coches autónomos hasta salud y poder dar visión -al fin- a los robots 😉
Si te suscribes salvas un gatito (o no)
Recibe los próximos artículos sobre Machine Learning, estrategias, teoría y código Python en tu casilla de correo!
NOTA: algunos usuarios reportaron que el email de confirmación y/o posteriores a la suscripción entraron en su carpeta de SPAM. Te sugiero que revises y recomiendo que agregues nuestro remitente info @ aprendemachinelearning.com a tus contactos para evitar problemas. Gracias!
Aún no realizaste el ejercicio práctico de detección de objetos con Python, Keras y Tensorflow? Anímate!
El libro del Blog
Si te gustan los contenidos del blog puedes comprar el libro en papel ó en
formato digital (el precio lo pones tú!)…